
IBMさんからOllamaに対応したIBM Granite 3.0 modelsがリリースされたというニュースがありました(2024.10.21)。
ラスベガスで行われているTechXchange Conference 2024に合わせた発表なのかなと。
これまで、IBMのLLMでOllamaに対応していたのは主にGraniteCodeという特定のモデルでしたが、用途が限定されていたため、汎用性のあるモデルが登場するのを待っていました。早くIBMCloudにあったGranite Japaneseがオープンソース側にも反映されてこないかなと思っていたのですが、今回のリリースでChat的なLLMモデルが発表されたので早速使用してみます。
発表されたLLMモデル
発表されたLLMモデルは以下の2つとなります。
- 最先端のオープンモデルと同等のパフォーマンス(
Granite3-dense 2B、Granite3-dense 8B) - 特定のタスクに特化したサブモデル化し高速な応答に対応した(
MoE)モデル(Granite3-moe 1B、Granite3-moe 3B)
ちなみにどちらもApacheライセンスになっています。
最先端のオープンモデルと同等のパフォーマンス(Granite3-dense 2B、Granite3-dense 8B)
Granite 2BとGranite 8Bは、テキストのみを扱う高密度(サイズの割に非常に高い言語理解・生成能力を持つ)な大規模言語モデル(LLM)です。これらのモデルは、12兆以上のトークン(言語の基本単位)のデータを使って訓練されました。IBMの初期テストでは、これらのモデルが前バージョンと比べて性能と速度の両面で大幅な改善を示しました。特に、Granite 8B Instructは、OpenLLM Leaderboard v1とv2の両方のベンチマークテストにおいて、Llama 3.1 8B Instructと同等の性能を発揮しています。(ニュースリリースの翻訳)
こちらはどちらかというと最近よくあるLLMとほぼ同等の性能を持ったLLMモデルといえばいいでしょうか。
特定のタスクに特化したサブモデル化し高速な応答に対応した(MoE)モデル(Granite3-moe 1B、Granite3-moe 3B)
1Bと3Bのモデルは、低遅延使用向けに設計されたIBM初のMoE(Mixture of Expert)Graniteモデルである。 このモデルは10兆トークンを超えるデータで学習され、Granite MoEモデルは、オンデバイス・アプリケーションや瞬時の推論を必要とする状況での展開に理想的です。(ニュースリリースの翻訳)
こちらは高速性を重視したモデルで、よりチャットなどのインターフェースに使いやすいモデルであり、軽量なためEdgeデバイス向けとも言えます。
折角、Ollamaに対応したという話なので、手元にあるDockerベースのOllamaで使用します。
使用環境
今回、使用環境としてはUbuntu24.04にDockerをインストールし、OllamaコンテナでLLMモデルを試してみます。
neofetchの出力は以下の通りです。CPUは第8世代Intel Core i7なのでかなり古めですね。あと、GPUもNVIDIA GeForce GTX 1070 Mobile(VRAM8GB)が搭載されています。CPUのみの動作よりは高速に動くでしょう。

- OS: Ubuntu 24.04 LTS x86_64
- Host: GS65 Stealth Thin 8RF REV:1.0
- Kernel: 6.8.0-44-generic
- CPU: Intel i7-8750H (12 cores) @ 4.10GHz
- GPU (Primary): NVIDIA GeForce GTX 1070 Mobile
- GPU (Integrated): Intel CoffeeLake-H GT2 [UHD Graphics 630]
- Memory: 16000MiB
NVIDIA Container ToolkitとDockerのインストールはすでに行われているものとします。インストールに関しては以下を参照してください。
NVIDIA Container Toolkitのインストール
UbuntuにDockerをインストール
Ollamaコンテナの起動
では、DockerでOllamaコンテナを起動します。今回のGraniteは最新(バージョン0.3.14)のOllamaコンテナのイメージで動作しますので、すでにコンテナを作成している方も最新のコンテナをpullしてコンテナを作成してください。
GitHubのバージョンリリースページにも以下の画像がありますので対応がわかります。

Ollamaコンテナの起動は以下を参考にしてください。今回はデータの永続性を図るため~/ollamaとコンテナの/ollamaディレクトリをマウントしています。
参考
GPUを使用する場合には以下のコマンドを実行します。
$ mkdir ~/ollama # ホストとのファイル共有ディレクトリ作成 $ docker run -d --gpus=all -v ~/ollama:/ollama -p 11434:11434 --name ollama ollama/ollama
GPUがない場合(CPUのみを使用する場合)には以下のコマンドを実行します。
$ mkdir ~/ollama # ホストとのファイル共有ディレクトリ作成 $ docker run -d -v ~/ollama:/ollama -p 11434:11434 --name ollama ollama/ollama
これでコンテナが作成され、起動状態になりました。2回目以降は以下の様に起動します。
$ docker start ollama
これでOllamaコンテナの準備が整いました。
Ollamaを実行しLLMを使用してChatを開始する
コンテナが起動したので、あとはOllamaからLLMを読み込んで実行を行います。以下のどちらかを選択してください。
# LLMにgranite3-dense:8bを使用する場合 $ docker exec -it ollama ollama run granite3-dense:8b # LLMにgranite3-moe:3bを使用する場合 $ docker exec -it ollama ollama run granite3-moe:3b
granite3-moe:3bを使用してOllamaを起動
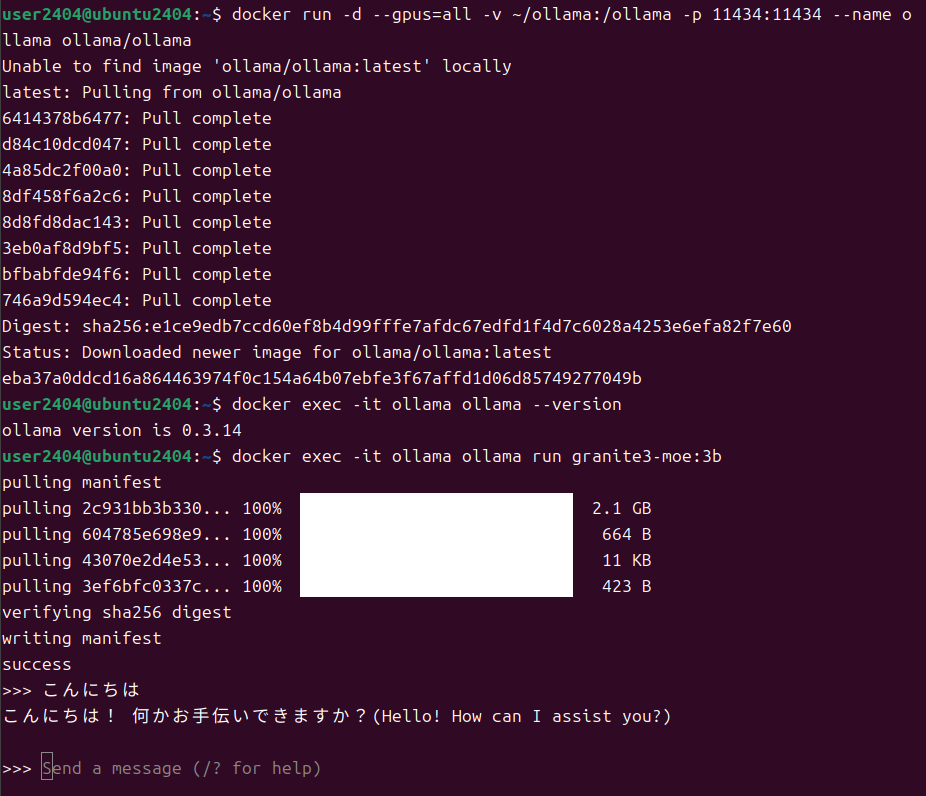
今回リリースされたLLMモデルであればVRAMが8GBであれば問題なく動作しますので、最近であればGeForce RTX 3050くらいが相当すると思います。私のように古いものを使用していてもVRAMが8GBあれば大丈夫です。また、granite3-moeに動作を限るならば、VRAMが4GBのものでも動作しますので、GeForce GTX 1650あたりでも動作すると思います。
OllamaのLLMとチャットを行う。
granite3-moe:3bの使用
早速、チャット向きと思われるgranite3-moe:3bを使用してどの程度の反応が返ってくるかを試してみます。
日本語で以下のような質問をしてみましたが、GPUのおかげで、モデルの応答速度がCPU使用時よりも数倍速く感じられます。ChatGPTなどネットワークサービスからの返答スピードより少し早く感じました。

ただ、なんとなく物足りない感じの生成結果かなと思います。プロンプトを長くすればもう少し良い答えが帰ってきそうですが、チャットの実験としてはそこまで長い文章をいれないかなとも思います。もう少し実験をしてみたい感じです。
granite3-dense:8bの使用
先ほどの実験ではいい感じの印象があったのでgranite3-dense:8bを使用してみます。Llama 3.1 8B Instructレベルというリリースにもあったので、ちょっと期待してテストしてみます。今回はからあげの作り方を聞いてみました。
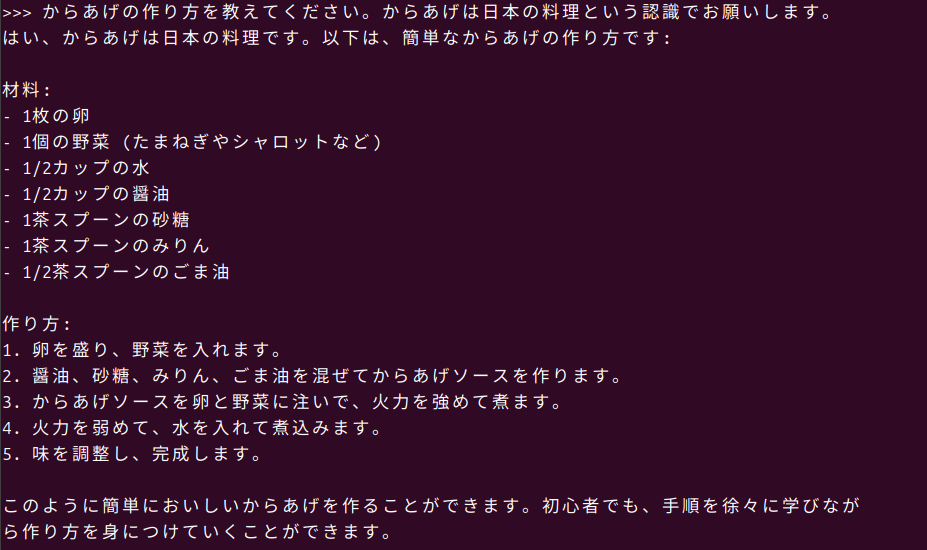
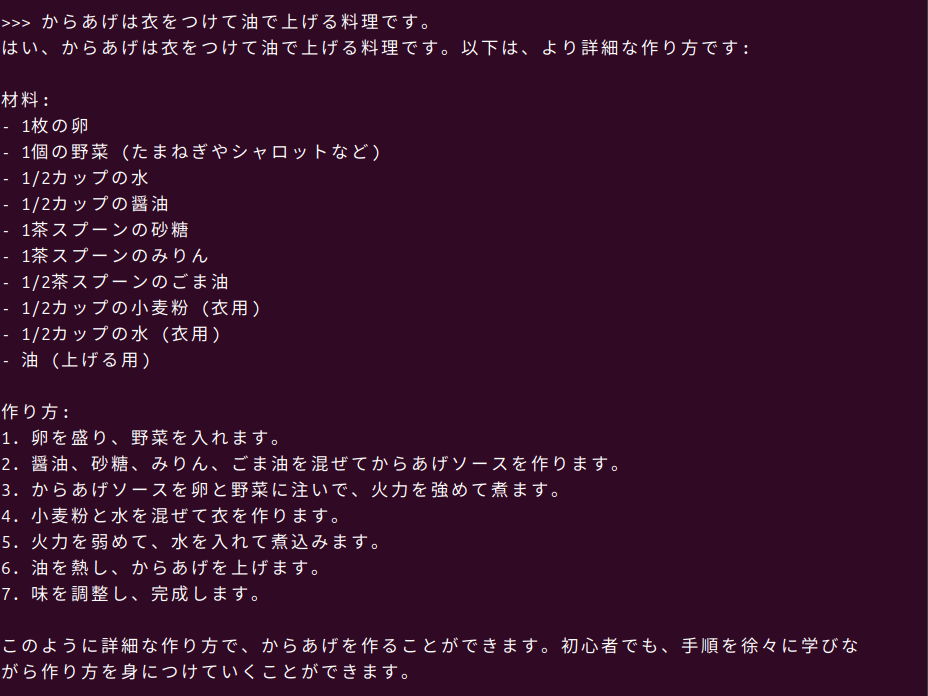
からあげという料理が認識できなかったのでハルシネーションが発生しています。揚げ物ということをその後のプロンプトで教えることで、比較的近い内容の答えを返してくれました。一般的なLLMなのでプロンプトの書き方をもう少し工夫すれば、もう少しレベルを上げる期待感はありますね。 こちらもGPUを使用しているのでかなり良いスピードで回答してくれていますが、VRAMの使用容量が9割ほどになっているので、これ以上のサイズは難しいでしょう。
おわりに
今回はリリースがあったのでスピード重視で実験をしてみました。オープンソースのOllama上でIBM Graniteがスムーズに動作し、実際に使えるAIチャットとしての可能性が見えてきたかなと思います。特にGPUを活用することで、高速な応答を実現できる点が魅力かなと思いました。Ollamaを使用することで初心者でも様々なLLMを手軽に試せるようになってきています、興味がある方はぜひチャレンジしてみてください。