最近では、生成系AIも徐々に多様化してきて、ローカルLLMの使用も流行ってきていますね。個人利用であれば、OpenAIのChatGPTなどのSaaS型の生成AIでも問題ないのですが、企業活動になるとそう言ってもいられない事象があるのはもっともかもしれません。
今回は、先日まで設定を行っていた作成した中古ゲーミングPCのUbuntu24.04 LTS上にDocker(CUDA Toolkit設定済)を使用していますが、Dockerが使用できるようであればCPUのみでも実行可能です(処理スピードの点は注意)。また、WindowsのDockerやWSLでもほぼ同様に使用できると思います。

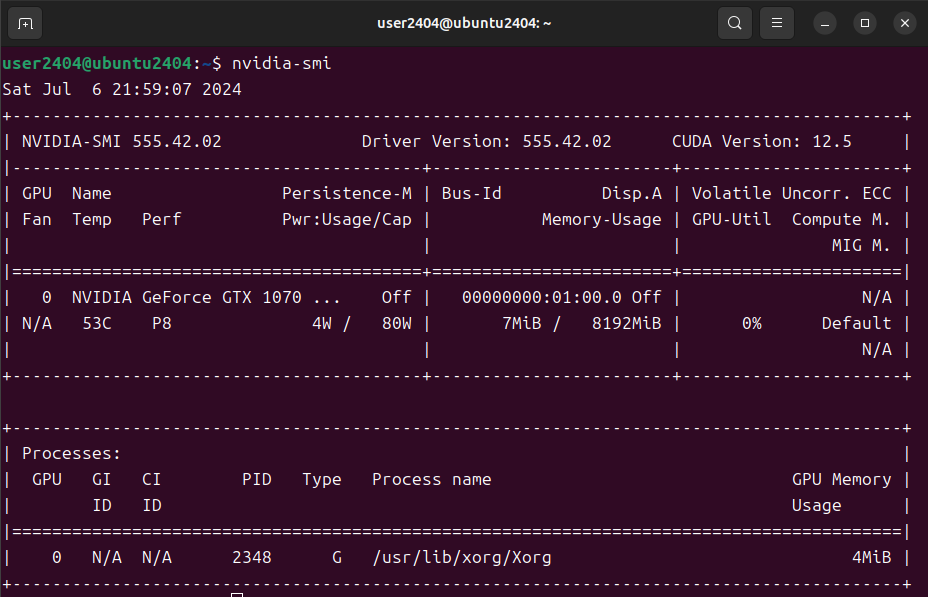
参考
ただ、環境構築やCLI上からプロンプトを打ち込むのは結構面倒なので、今回はローカルLLMをWebUIから操作することのできるopen-webuiという環境も使用して一般的なチャットインターフェースを持った生成系AIの形で利用できるようにしてみたいと思います。
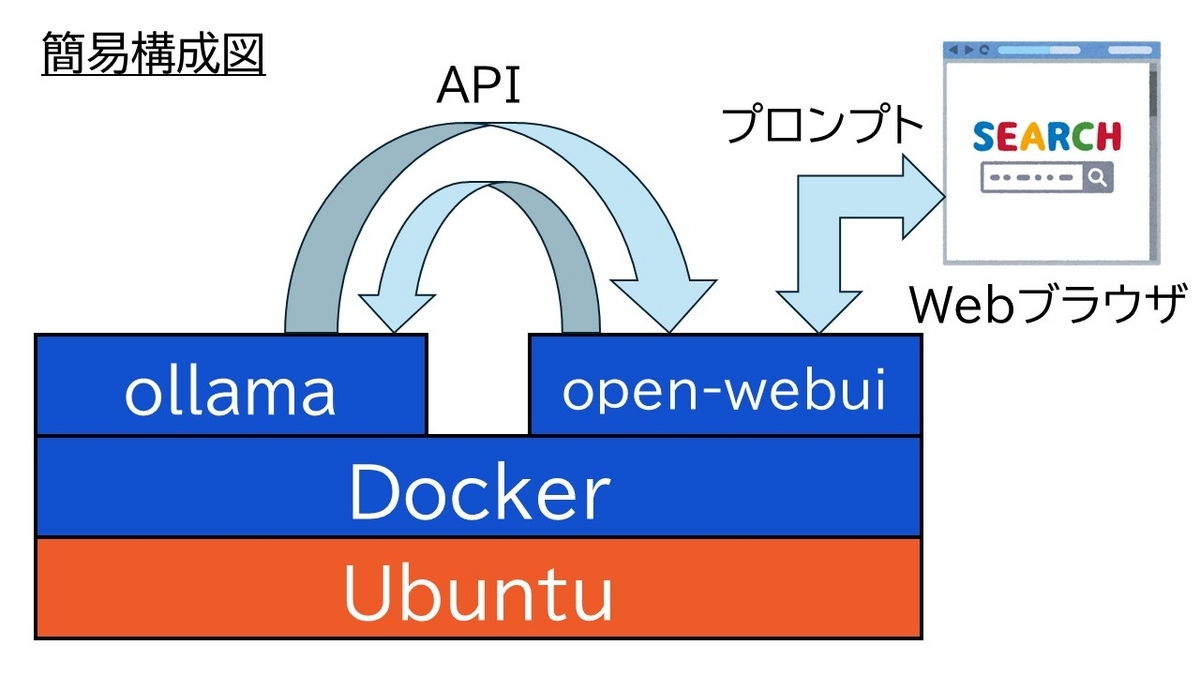
ローカルLLMとは?
ローカルLLMはクラウドではなく、ローカル環境(オンプレミス)で動作する大規模言語モデルのことを指すようです。
今回はこのローカルLLMを使用する仕組みとしてOllamaを使用してみたいと思います。
Ollamaとは…
Ollamaは、オープンソースの大規模言語モデル(LLM)をローカルで簡単に実行できるツールです。LLama3やLLava、vicuna、Phiなどのオープンに公開されているモデルを手元のPCやサーバーで動かすことができます。
このような形でLLM部分のみを変更することで、1システムで切り替えて使用できるというのがOllamaのメリットだと思います。更に今回はDockerのコンテナを使用することで更に手軽に使用できるようにしてみたいと思います。
コンテナの作成
これから必要となるollamaとopen-webuiの2つのコンテナを作成します。
ollamaコンテナの設定と作成
DockerHubにollamaのイメージがあるのでそれを使用します。データなどの永続化も考慮して-vでローカルストレージのマウントもしておきましょう。
まず、データの永続用のディレクトリ(今回は~/ollamaにしています)を作成します。また、このコンテナとの通信に使用するポートは11434ポートを使用するため、ホスト側と共有できるように-pを使用してください。以下の様コマンドを実行しします。今回のコンテナではGPUの機能を使用するので--gpus=allも追加しています。
GPUのある環境では
$ mkdir ~/ollama # ホストとのファイル共有ディレクトリ作成 $ docker run -d --gpus=all -v ~/ollama:/ollama -p 11434:11434 --name ollama ollama/ollama

GPUの無い環境(CPUのみでの動作)では
$ mkdir ~/ollama # ホストとのファイル共有ディレクトリ作成 $ docker run -d -v ~/ollama:/ollama -p 11434:11434 --name ollama ollama/ollama
2回目の以降のコンテナの起動
$ docker start ollama
これでollamaコンテナが作成できました。
open-webuiコンテナの設定と作成
続く、open-webuiコンテナについても同じくDockerHubにイメージがあるので、そこから取得します。ファイルの永続化もできるようにマウントも忘れずに(今回はディレクトリを~/open-webuiとしています)。
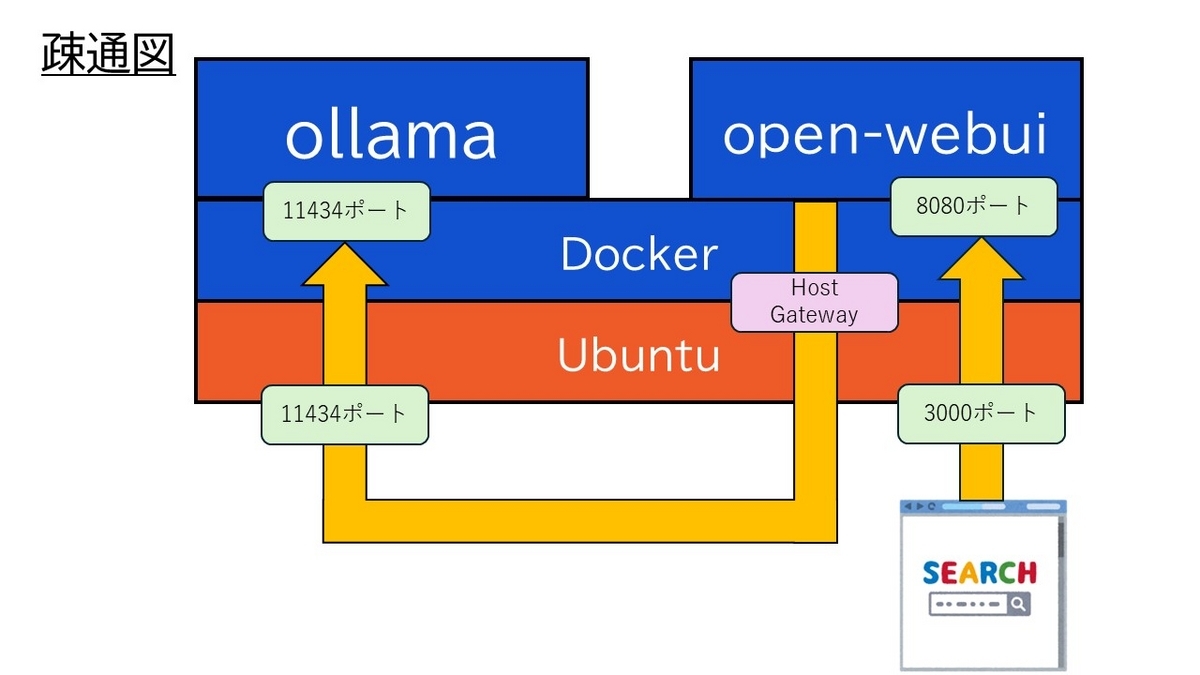
このコンテナは、先ほど作成したollamaコンテナとも通信を行います。そのため、--add-host=host.docker.internal:host-gatewayを使用しています。これはこのコンテナからホスト側のポートを経由して通信を行うという意味です。図にすると以下の様になります。これでもわかりにくいですが…。このような方法を取っているのはollamaコンテナの操作も楽にできるようにする工夫だと思ってもらえれば大丈夫です。
【ホストのブラウザ】<---(3000→8080)--->【open-webuiコンテナ】<---><Host Gateway><---(11434→11434)--->【ollamaコンテナ】
$ mkdir ~/open-webui # ホストとのファイル共有ディレクトリ作成 $ docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v ~/open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
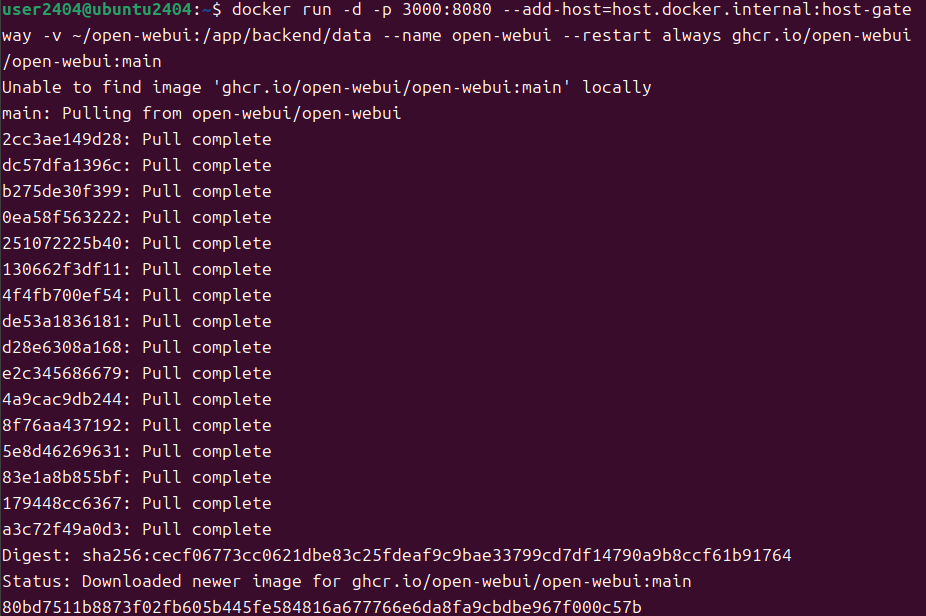
open-webuiコンテナを作成できました。こちらはWebサーバの役割を行うので、起動後に触る必要はなく、Webブラウザでアクセスをするだけになります。
作成後はDocker Desktopなどからコンテナ起動を行うことも可能です。
これで必要となるDockerの2つのコンテナは準備できました。早速実行していきましょう!
Ollamaの動作テストを行う
この2つのコンテナが動作している前提で動作を行っていきます。Ollamaはコンテナ上にあるollamaコマンドにLLMモデルを指定することで該当のLLMを動作させることができます。
例えば、llama3をLLMとして使用するには以下のコマンドを実行します。ollamaコンテナでollama run llama3というプロセスを実行させています。
# LLMにllama3を使用する場合 $ docker exec -it ollama ollama run llama3

その他のLLMモデルを使う例も載せておきます。使用可能なLLMモデルに関しては以下を参照してください。各モデルのページに起動コマンドが書かれています。
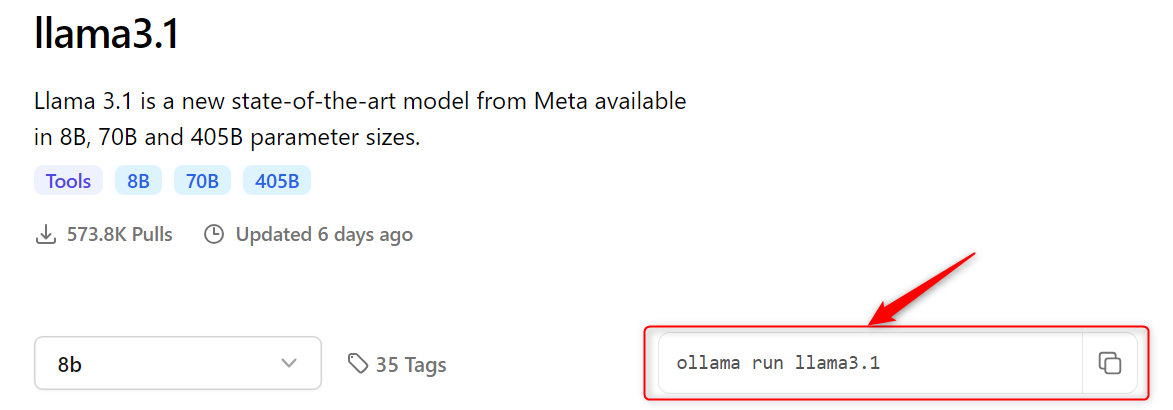
# LLMにphi3:3.8bを使用する場合 $ docker exec -it ollama ollama run phi3:3.8b

# LLMにgranite-codeを使用する場合 $ docker exec -it ollama ollama run granite-code

LLMモデルがコンテナ内にない場合には、Pullをしてダウンロードを行ってくれるのでダウンロードが終わるまで待機しましょう。2回目以降はダウンロードは行われません。
コマンド実行後(Pullが終わったら)には、対話型のプロンプトがでるので、テキストを入力すると返答が帰ってきます。
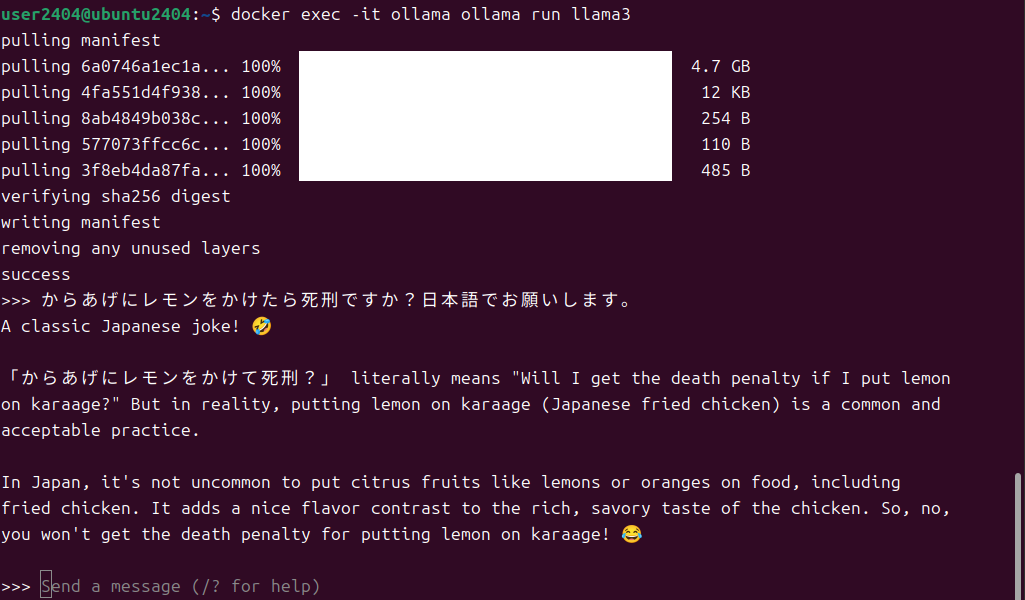
この例では日本語と指定しましたが、英語で返答されています。
これでOllamaの動作テストは無事にできました。
Webブラウザ経由で動作確認を行う
ここまでできたら今度はopen-webuiコンテナへWebブラウザからアクセスを行ってみます。
アクセス後にユーザー認証画面がでてきますが、ネットワーク上にアクセスはしないので適当なデータでも大丈夫です。

ログインするとWebUIが表示されます。
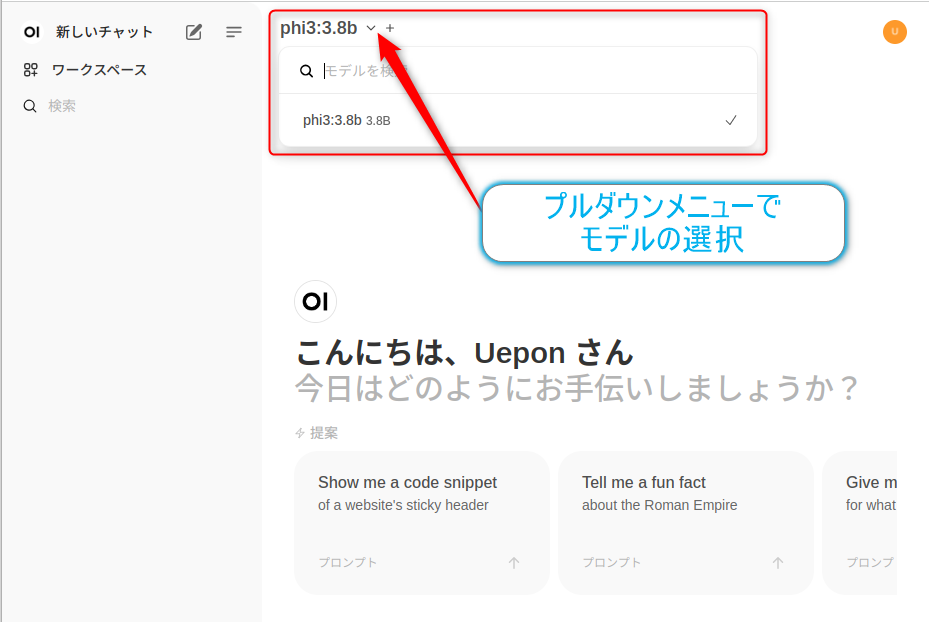
画面上部で使用するモデルを選択して
プロンプトを入力すると
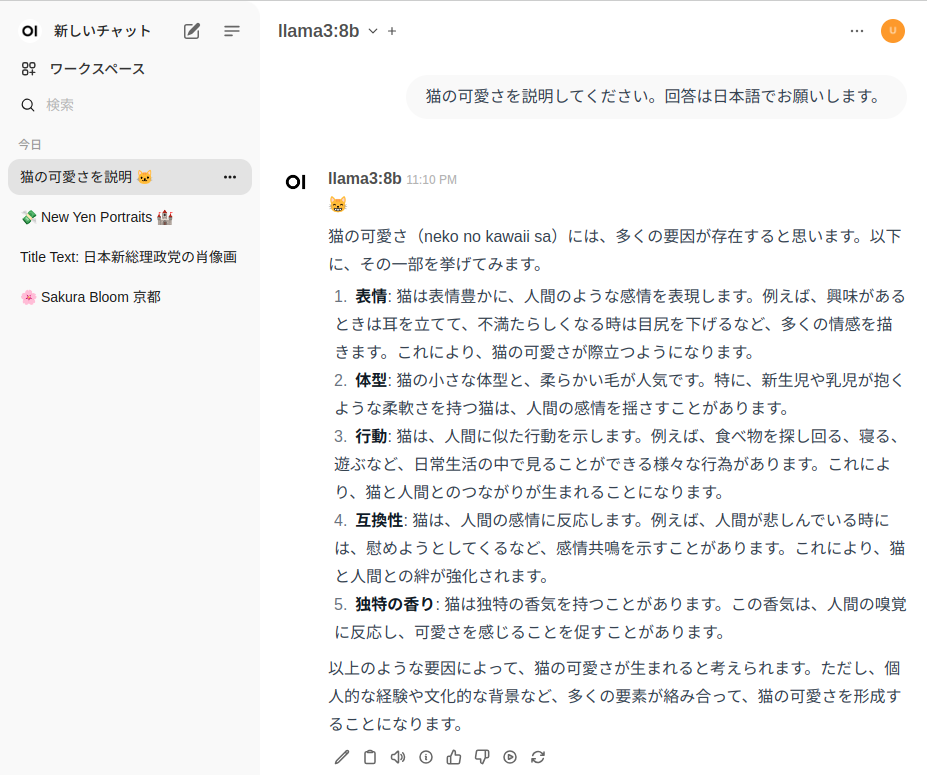
実行結果が表示されました。
では、今回は少し目線をかえてIBMさんの新しいLLMモデルであるGraniteを使用してみようと思います。
Graniteは
Granite Code Modelsは、IBMが開発した116種類のプログラミング言語で訓練された LLM で、コード生成、バグ修正、コード説明、ドキュメント化などの幅広いタスクに対応できるように設計されています。これらのモデルは、エンタープライズソフトウェア開発の生産性向上を目指しており、3Bから 34B までのモデルサイズがあります。
とのこと、主にビジネスを見据えたのLLMモデルといっていいでしょう。
再掲(既に起動している場合には実行は不要)
# LLMにgranite-codeを使用する場合 $ docker exec -it ollama ollama run granite-code
このLLMモデルは英語のみ対応なので、プロンプトに日本語を入力すると、途中で日本語から英語に変えられてしまいました。英語の入力を行えばもちろん問題なく返答してくれるので、マルチリンガル化を待ちたいと思います。
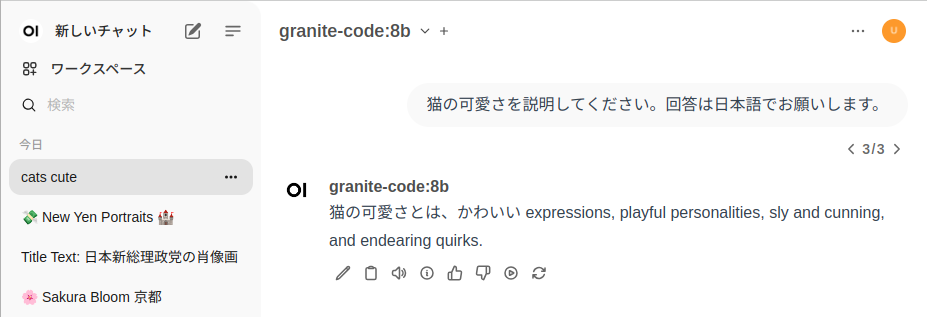
LLMモデルを切り替えるには、コンソールから再度、LLMモデルを指定してollamaを起動してください。
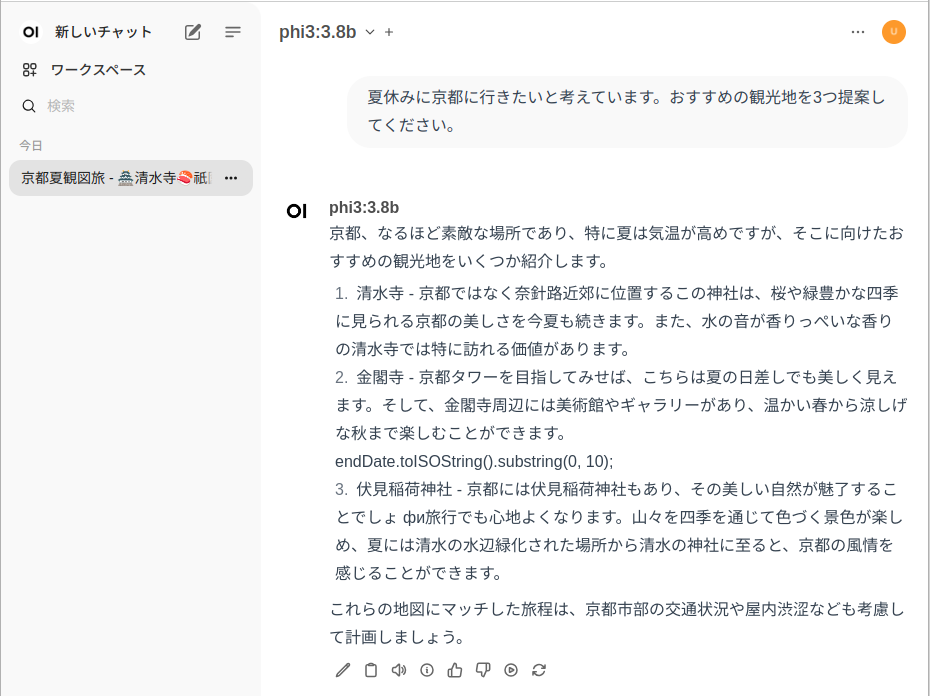
上記のモデルに切り替えてみます。
再掲(既に起動している場合には実行は不要)
# LLMにphi3:3.8bを使用する場合 $ docker exec -it ollama ollama run phi3:3.8b
Web-UI上でモデルの切り替えを行って、
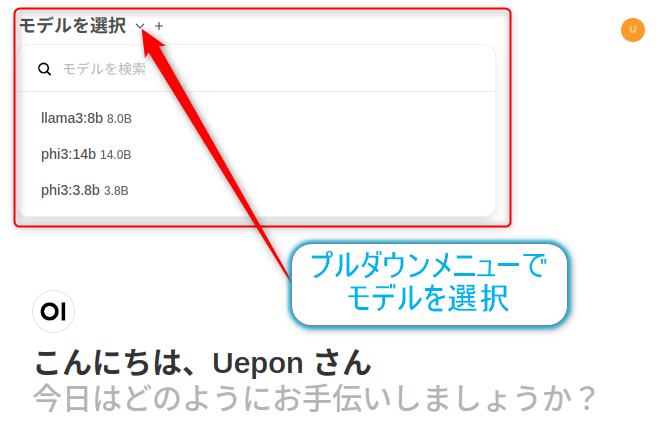
プロンプトを入力すると、シームレスにモデルの切り替えができます。
コンテナの停止(システムの停止)
終了するにはコンテナの停止を行います。Dockerデスクトップでも停止できますし、以下のようなコマンドで停止させることもできます。※以下のコマンドでは全てのコンテナを停止させるので注意してください。
$ docker stop $(docker ps -q)
#おわりに
今回はDockerコンテナを使用してUbuntu上にローカルLLMの環境を構築してみました。LLMモデルも簡単に変更できる点やWebUIを使用する事もできるので非常に使いやすい環境です。今後はLLMもコンパクトなサイズのバリエーションも増えてくるので、ますますローカルLLMの世界も広がっていくのではないかと予想しています。
参考リンク