最近、AIのことは一応触ってはいますが、ちっともわからない状況です🫠
先日までOllamaを使用していたのでローカルLLMについてはなんとなく分かってきた様でもありという状況ですが、OllamaはGGUF形式のモデルが使えるとはいえ、すべてのモデルがGUFF形式で公開されているというわけはありません。
リポジトリ内には拡張子が無いモデルのファイルがあって…これ何?って感じです。なんとなく分かってきたのはHuggingFaceにで公開されているモデルはHFって呼ばれるモデルのようですが…。どこかに名言されてるんでしょうか🙇
ということで、HuggingFaceに公開されているHFモデルをなんとかしてOllamaでも使用可能なGGUF形式に変換できないかという内容でチャレンジしてみたいと思います。
(2024.09.11)Ollamaに作成したGGUF形式のモデルをpullする方法のリンクを追記
【参考】 今回はWindows11(WSL)のUbuntu24.04 LTS環境で行っていますが、ピュアなUbuntu24.04 LTSでも動作を確認しています。 今回はUbuntuのバイナリのビルドがあるので、念の為に以下のパッケージをインストールしておきます。また、 調べてみると、 再掲 これを元に自分でもチャレンジしてみます。張り切って車輪の再発明しますよ🤩🤩🤩 記事の中では Port of Facebook's LLaMA model in C/C++(GitHub - ggerganov/llama.cpp: LLM inference in C/C++) また、 まずは クローンした (注意)pythonやpipは必要であればpython3やpip3に置き換えてください。 こちらでPythonプログラムの準備は完了です。 続いては 【参考】llama.cppバイナリビルド説明
github.com 成功すれば 変換準備ができたので 今回は、 まずは このままでいいはずなのですが、 そんなときには【Ctrl+C】を押下して、以下のようにコマンドを実行します。HuggingFaceではサイズの大きなモデルは HuggingFaceのリポジトリに これで問題なくダウンロードされるはずですが、それでもだめなときもあります。そんなときは こちらは2つ目の方法になります。 7shiさんのサイトではHuggingFaceのページにあるPythonのサンプルコードを修正することで対応できるという風に書いてあったので、それを修正してコマンドライン実行できるものをつくってみました。 【該当箇所】 https://qiita.com/7shi/items/14d24a25aa26dcf97d2d#clone (注意)このPythonではライブラリにtransformersが必要なるので以下を実行してライブラリをインストールをしてください。 以下のプログラムを実行します。引数にはモデル名を入れてください。例えばDataPilot/ArrowPro-7B-KillerWhaleというような形式です。 実行後でダウンロードされたmodelとtokenizerは"~/.cache/huggingface/hub/"に格納されますが、指定する場合には環境変数のHUGGINGFACE_HUB_CACHEにパスを設定してください。 HuggingFaceからLLMモデルを取得するアプリ HuggingFaceからmodelとtokenizerをダウンロードするコード 実行の様子 取得されたファイル 上記2つのどちらかの手法でファイルが取得できたら、 手順としては という手順を行います。量子化を行うことでサイズも小さくできるのでメモリが足りない場合などでも効果があるのではないでしょうか。 (その1)Git Cloneでモデルの取得を行った場合 (その2)掲載のPythonプログラムでモデルの取得を行った場合 ※モデルパスに注意 今回は 変換し、 さらに、 作成されたモデルのファイルサイズも圧倒的に小さくなっています。 これで 以前のエントリ同様に 【参考】 モデルの設定ファイルを例えば以下のように作成し Modelfile_ArrowPro-7B-KillerWhale-Q4_K_M 別途、 以下はWindowsの 以下のように実行します。今回は ※モデルファイルはDocker側から参照できるパスにしておきましょう。(Dockerコンテナ側のパスになるため、PowerShellからのパス補完は行われません。)
うまくモデル設定ができたので、つづいて実行を行います。 無事起動できたのでプロンプトを入れてテストをしてみます。 問題なさそうですね。唐揚げのレシピについて聞いてみると 若干怪しい記述もありますが、問題なく使用できています。 HuggingFaceに公開されている これで公開されていほぼほとんどのモデルのテストができるようになったかな?🤩🤩🤩 ※コメントでOllamaに作成したGGUF形式のモデルをpullする方法を教えていただいたので追記いたします。(2024.09.11)
【参考】 【過去記事】動作の前提
Pythonのvenvやpipもデフォルトではインストールされていないこともあるので動作を確認しておいてください。$ sudo apt update
# pipとvenvのインストール(もしなければ)
$ sudo apt install python3-pip python3-venv
# バイナリのビルドツールとgit関連のインストール
$ sudo apt install build-essential git git-lfs
git-lftはHuggingFaceでも使用されている大容量ファイルを扱うためのものになります。Windows版のGitにはこの機能が含まれているそうです。GGUF形式のモデルへの変換方法の調査Hugginfaceで公開されているモデルを積極的にGGUFモデルに変換されている7shiさんがQiitaにエントリで書かれていました。llama.cppが必要のようです。Ollamaは内部的にllama.cpp(のサーバ機能)を利用しているもののようで、ローカルLLMといえば、これっていうもののようです。ただ、cppとの記載がある通り、C++のソースコードのビルドが必要となります。llama.cppにはその他に使用できるツールも同梱されており、ただローカルLLMを使用するだけというものでは無いようです。今回の変換ツールも、このllama.cppに同梱(ビルドで生成されるものを含む)されています。llama.cppを使用するための準備llama.cppの取得とビルドllama.cppをGitHubから取得します。llama.cppは以下のリポジトリにあるので、CLIでCloneを行います。$ git clone https://github.com/ggerganov/llama.cpp
git cloneコマンドで取できたら、続いてllama.cppのビルドを行っていこうと思います。llama.cppに含まれるPythonの実行ファイルのための準備llama.cppのソースコードにはPythonの実行ファイルも含まれています。そちらはビルドしなくても動作させることができます。ただ、Python用のライブラリを準備(インストール)する必要があるので、その作業を事前に行っておきます。# クローンディレクトリの移動
$ cd ~/llama.cpp
# llama.cpp用の仮想環境の準備(今回は**.llama.cpp**として、llama.cppのクローンディレクトリの中に作成します。)
$ python -m venv .llama.cpp
$ source ./.llama.cpp/bin/activate
(.llama.cpp) $ pip install -r requirements.txt
llama.cppのビルドllama.cppのビルドを行っていきます。以下のリンクを参考にビルドを行っていきましょう。# クローンディレクトリへの移動
$ cd llama.cpp
# バイナリのビルド
make
# 成功したらホームディレクトリに戻る
cd ~
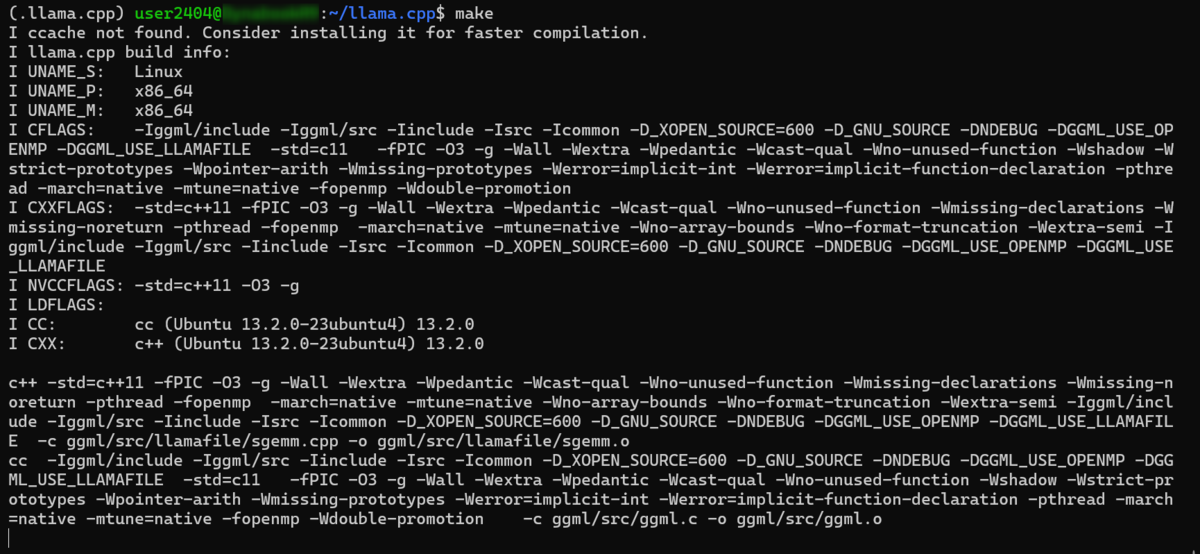
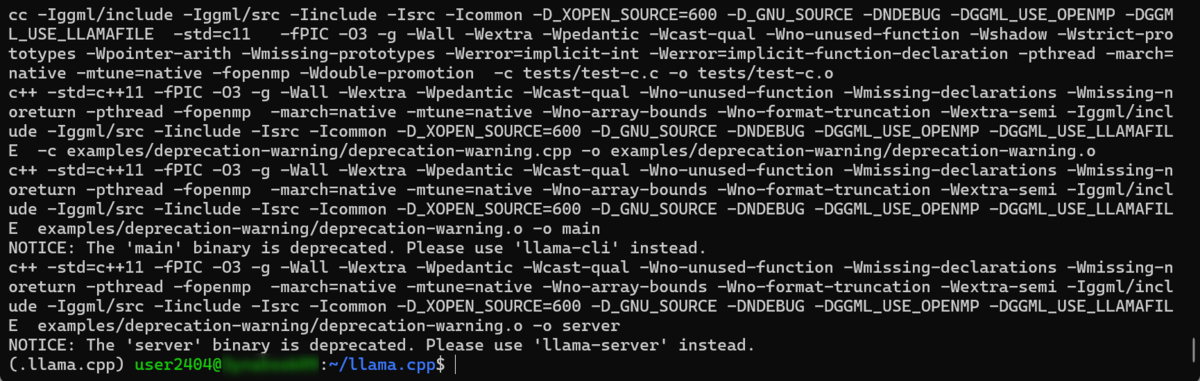
llama.cppのバイナリ構築は完了です。
これでHFファイルをGGUF形式に変換するプログラムの準備は整いました。GGUFモデルへの変換
GGUF形式のモデルに変換するHFモデルを取得します。今回はDataPilot/ArrowPro-7B-KillerWhaleをHuggingFaceからダウンロードします。すでにGGUF形式のモデルはHuggingFace上に存在しますが、参照先と同じことをしてみます。
Gitを使用する方法とPythonを使用する方法の2つの方法を紹介します。基本的にはどちらを使用しても可能処理は可能ですが、どちらも一長一短があるかもしれません。(その1)GitのコマンドでのLLMモデルの取得(一般的な方法)
Gitを使用してモデルのリポジトリのファイルを取得する方法です。Git Cloneコマンドを使用してリポジトリを取得する方法は大きく変わりません。# LLMのダウンロード(SafetensorsモデルというかHFモデル)
# Hugginfaceのリポジトリからgit cloneコマンドで取得
$ git clone https://huggingface.co/DataPilot/ArrowPro-7B-KillerWhale
Git Cloneの処理の途中で停止してしまいました。
LFSという仕組みによって保存されているので、このようなファイルがある場合にはgit lfsコマンドでダウンロードします。# クローンしたディレクトリへ移動
$ cd ArrowPro-7B-KillerWhale/
$ git lfs pull
LFSとかかれているファイルがその対象になります。
wgetコマンドで取得するのも手です。リポジトリのファイルのリンクをwgetコマンドの引数にして実行してください。最初からwgetコマンドで取得するのも手なのかもしれないのですが🫠(その2)LLMモデルの取得(専用スクリプトを使用する方法)

ライブラリのインストール
$ pip install transformer
LLM取得アプリのソースコード

~/.cache/huggingface/hub/models--DataPilot--ArrowPro-7B-KillerWhale/snapshots/ 以下にモデルの実体があります
GGUF形式モデルに変換する処理に移ります。GGUF形式のモデルへの変換1.
BFloat16のGGUF形式モデルに変換# BFloat16(bf16)へ一旦変換
$ python ~/llama.cpp/convert_hf_to_gguf.py --outfile ArrowPro-7B-KillerWhale-bf16.gguf --outtype bf16 ArrowPro-7B-KillerWhale

~/.cache/huggingface/hub/models--DataPilot--ArrowPro-7B-KillerWhale/snapshots/ 以下にモデルの実体があります# BFloat16(bf16)へ一旦変換
# モデルパスに注意
# モデルの実体は以下に格納されています
# ```~/.cache/huggingface/hub/models--DataPilot--ArrowPro-7B-KillerWhale/snapshots/```
$ python ~/llama.cpp/convert_hf_to_gguf.py --outfile ArrowPro-7B-KillerWhale-bf16.gguf --outtype bf16 ~/.cache/huggingface/hub/models--DataPilot--ArrowPro-7B-KillerWhale/snapshots/63a8746d41285207538662a8eb052a7461f79d22

BFloat16(bf16)のGGUF形式のモデルが作成されました。
2.
Q4_K_Mに量子化Q4_K_Mの量子化を行います。(ここからは同じ作業になります。)# Q4_K_Mへ変換
$ ./llama.cpp/llama-quantize ArrowPro-7B-KillerWhale-bf16.gguf ArrowPro-7B-KillerWhale-Q4_K_M.gguf Q4_K_M

GGUF形式のLLMモデルが生成できました。最後にこちらをOllamaでロードしてみたいと思います。生成した
GGUF形式のモデルをOllamaで使用してみるOllamaを使用していきます。OllamaでGGUF形式のLLMを使用するFROM /ollama/ArrowPro-7B-KillerWhale-Q4_K_M.gguf
Dockerなどでモデルを設定します。先程はWSL上でGGUF形式のモデルを作成していましたが、このモデルファイルは別の処理系に持っていっても問題なく使用することができます。では、モデル設定をします。Docker上で動作を行っています。以下のようにあらかじめ作成していたコンテナを起動し、PS> docker start ollama
ArrowPro-7B-KillerWhale-Q4_K_Mと設定しています。PS > docker exec -it ollama ollama create ArrowPro-7B-KillerWhale-Q4_K_M -f /ollama/Modelfile_ArrowPro-7B-KillerWhale-Q4_K_M

PS> docker exec -it ollama ollama run ArrowPro-7B-KillerWhale-Q4_K_M

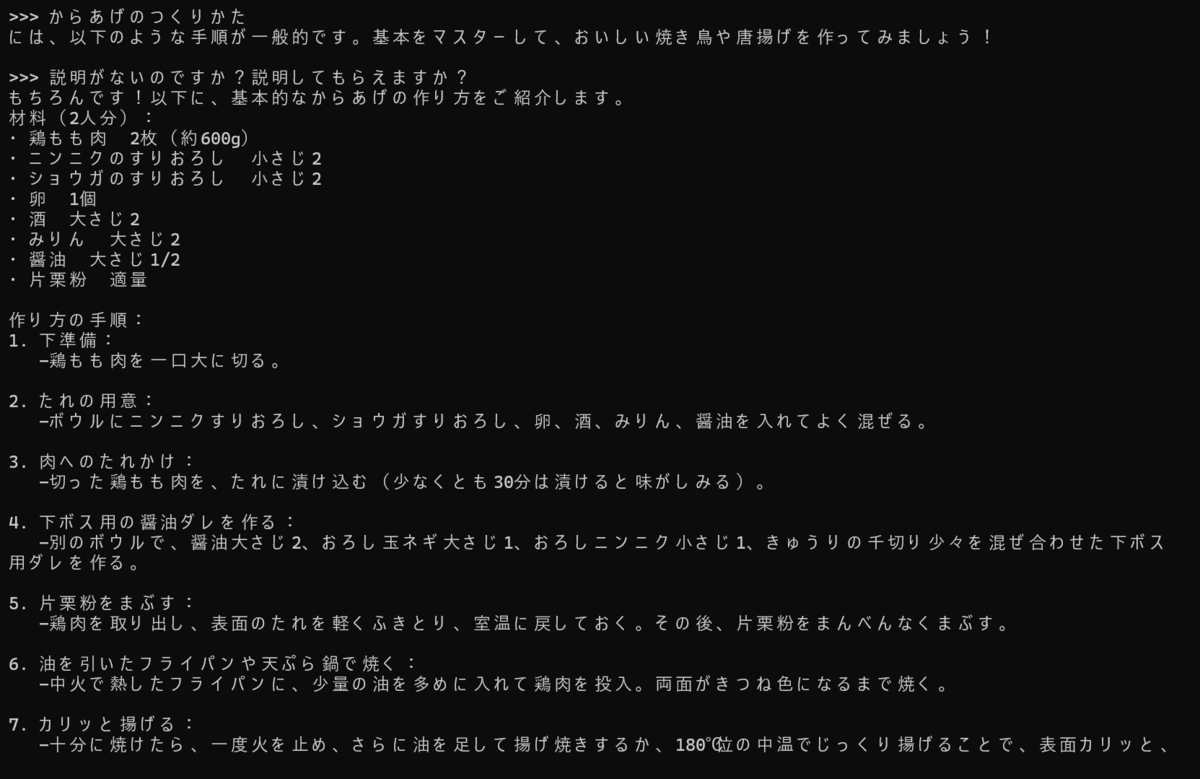
おわりに
LLMモデルを取得・変換し、GGUF形式への変換とともに量子化し、Ollamaで動作できるように設定を行いました。追記