AI界隈の動きで、LLM(大規模言語モデル)に興味を持ち始めた方も多いのではないでしょうか。自分もそんな1人です。今回は、自分のPCに搭載されているGPUがLLMをどれくらい効率よく動かせるのかベンチマークをについてセットアップ方法とベンチマーク結果をまとめています。llama.cppに含まれるllama-benchを使用します。
本音を言えば、Youtubeで紹介されるGPUのベンチマークはゲームのものがほとんどなので、LLMでの動作はどうなのよって思ったのでやってみたという内容です🤔海外サイトではLLMのベンチマークもあったりするんですけどね🙄ゲームのベンチマークは派手で見栄えはしますが…。かといってハローアスカベンチでStable Diffusionを入れるというのも面倒ですし。
- 1. llama.cppとは?
- 2. Ubuntu 24.04 LTSでのセットアップ方法
- 3. ベンチマーク用のモデルをダウンロード
- 4. ベンチマークを実行する
- 5. より詳細なベンチマーク情報を得る
- 6. ベンチマーク結果の見方
- 7. 結果を比較してみよう
- 8. まとめ
1. llama.cppとは?
llama.cppは、LLMを効率的に実行するためのオープンソースツールです。元々はMetaのLlamaモデルをCPUで動かすために開発されましたが、今ではさまざまなモデルをGPUでも動かせるようになっています。
以前、私のブログでも、LLMのモデルをGGUFモデルに変換するという内容書いています。
参考
2. Ubuntu 24.04 LTSでのセットアップ方法
必要なソフトウェアのインストール
まずはターミナルを開いて、必要なツールをインストールしましょう。
llama.cppはビルドが必要なアプリケーションなのでちょっと準備が必要になります。
# 事前に必要なアプリのインストール $ sudo apt install -y build-essential cmake git python3-dev python3-pip
llama.cppのクローンとビルド
次に、GitHubからllama.cppをダウンロード(クローン)してビルドを行います。
# llama.cppをクローン $ git clone https://github.com/ggerganov/llama.cpp.git
今回はGPUを使用するにはGPUドライバーとcuda-toolkitのインストールが必要になります。導入に関しては以下を参考にしてください。
参考
また、cuda-toolkitをインストールするとnvccというコンパイラもインストールされるのですが、PATHの設定が行われていないので、ここでPATH設定を追加しておきます。
# cuda-toolkitのnvcc(コンパイラ)を使用するため、PATHを設定 $ echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc $ echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc $ source ~/.bashrc
ここまでで、準備は完了です。以下を実行してビルドを行います。ビルド後の実行ファイルはllama.cpp/build/bin/に格納されます。今回欲しいllama-benchのバイナリもここに格納されます。
# llama.cppをビルド $ cd llama.cpp/ $ cmake -B build -DGGML_CUDA=ON $ cmake --build build --config Release
ビルドが正常に完了したことを確認するために llama-run --help コマンドを実行します。ヘルプが表示されれば成功です。
./build/bin/llama-run --help
3. ベンチマーク用のモデルをダウンロード
今回は日本語モデルとしてELYZA-japanese-Llama-2-7bを量子化したモデルを使います。Hugging Faceのmmngaさんのところからダウンロードできます。mmngaさんありがとうございます🙇
Hugging Faceからのモデルのダウンロードに関してはhuggingface-cliを使用しています。導入方法に関しては以下を参照してください。
参考
モデルのダウンロード
# モデルフォルダを作成 $ mkdir -p models # huggingface-cliでモデルをダウンロード # huggingface-cliが使用できない場合には事前に`pip install huggingface_hub`を行うこと $ huggingface-cli download mmnga/ELYZA-japanese-Llama-2-7b-gguf --local-dir models --include "ELYZA-japanese-Llama-2-7b-q2_K.gguf"
今回、私はVRAMが8GBのGPUを使っていますが、VRAMが4GB 、8GB、12GBで動くモデルを選択しています。このあたりベースになるのでちゃんと選んだほうがいいかなと思います。
量子化モデルについて
- q2_K: 2ビット量子化(最も小さいがやや精度が落ちる)… 4GBでも動作
- q4_K_M: 4ビット量子化(サイズと精度のバランスが良い)… 8GBでも動作
- q5_K_M: 5ビット量子化(より高精度だがサイズも大きい)… 12GBでも動作
12GBものはもう少し大きいモデルを選んでもよかったかもしれません💦
4. ベンチマークを実行する
ビルドおよびモデルのダウンロードが完了したら、ベンチマークを実行します。
# LLMのモデルを使用してベンチマークを行ってみる ./build/bin/llama-bench -m models/ELYZA-japanese-Llama-2-7b-q2_K.gguf
これでベンチマークが実行されます。
$ ./build/bin/llama-bench models/ELYZA-japanese-Llama-2-7b-q2_K.gguf ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce GTX 1070 with Max-Q Design, compute capability 6.1, VMM: yes | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | ------------: | -------------------: | | llama 7B Q2_K - Medium | 2.63 GiB | 6.74 B | CUDA | 1 | pp1024 | 295.37 ± 1.66 | | llama 7B Q2_K - Medium | 2.63 GiB | 6.74 B | CUDA | 1 | tg512 | 8.10 ± 0.21 | build: becade5d (4819)
この表示でpp1024とtg512がベンチマークに使用できる数値です。
5. より詳細なベンチマーク情報を得る
海外のLLMのベンチマークでは最初のトークンを出すまでの時間をベンチマーク値として使用していることも多いのですが、llama-benchではそれを表示できていません。しかたないので、llama-benchの結果から計算して表示するllama-bench-plus.shを作成します。(厳密には異なりますが、あくまでも参考値だと思います)
今回は以下のように計算しています。
最初のトークンを出すまでの時間= pp1024 + 1000 / tg512
llama-bench-plus.shの実行方法
./llama-bench-plus.sh <llama-benchバイナリのパス> <GGUF形式のLLMのモデル名>
llama-bench-plus.sh(最初のトークンを出すまでの時間に対応したベンチ‐マークスクリプト)
#!/bin/bash
# 引数の確認
if [ $# -lt 2 ]; then
echo "使い方: $0 <llama-bench のパス> <モデルのパス>"
exit 1
fi
# 引数から llama-bench のパスとモデルのパスを取得
LLAMA_BENCH_PATH=$1
MODEL_PATH=$2
# 使用するオプションを定義
BENCH_OPTIONS="-m $MODEL_PATH -p 1024 -n 512 -ngl 1 -b 2048 -r 3"
# llama-bench を実行し、結果を取得
RESULT=$($LLAMA_BENCH_PATH $BENCH_OPTIONS 2>&1 | tee /dev/tty)
# pp1024 (プロンプト処理時間) の取得 - 正規表現を改善
PP1024=$(echo "$RESULT" | grep -oP "pp1024\s*\|\s*\K[0-9.]+")
# tg512 (トークン生成速度) の取得 - 正規表現を改善
TG512=$(echo "$RESULT" | grep -oP "tg512\s*\|\s*\K[0-9.]+")
# First Token Latency の計算 (ms)
if [[ -n "$PP1024" && -n "$TG512" ]]; then
# bcコマンドの前に数値チェックを追加
if ! [[ "$PP1024" =~ ^[0-9.]+$ ]] || ! [[ "$TG512" =~ ^[0-9.]+$ ]]; then
echo "エラー: 数値以外の値が検出されました: PP1024=$PP1024, TG512=$TG512"
exit 1
fi
# 0での除算を防止
if (( $(echo "$TG512 == 0" | bc -l) )); then
echo "エラー: トークン生成速度が0です。除算できません。"
exit 1
fi
FIRST_TOKEN_LATENCY=$(echo "scale=2; $PP1024 + (1000 / $TG512)" | bc)
echo -e "\n=== ベンチマーク結果 ==="
echo "実行コマンド: $LLAMA_BENCH_PATH $BENCH_OPTIONS"
echo "----------------------------------"
echo "プロンプト処理時間:${PP1024} ms"
echo "トークン生成速度 :${TG512} トークン/秒"
echo "最初のトークン遅延:${FIRST_TOKEN_LATENCY} ms"
else
echo "エラー: ベンチマーク結果を取得できませんでした。"
echo "出力内容を確認してください:"
echo "$RESULT" | grep -E "pp1024|tg512" -A 1 -B 1
fi
このスクリプトをファイルに保存し、実行権限を付与します。
# スクリプトの作成と実行権限付与 $ nano ./llama-bench-plus.sh $ chmod +x llama-bench-plus.sh
実行すると以下のように表示されます。
# ELYZA-japanese-Llama-2-7b-q2_K.ggufを使用したベンチマーク $ ./llama-bench-plus.sh ./build/bin/llama-bench models/ELYZA-japanese-Llama-2-7b-q2_K.gguf ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce GTX 1070 with Max-Q Design, compute capability 6.1, VMM: yes | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | ------------: | -------------------: | | llama 7B Q2_K - Medium | 2.63 GiB | 6.74 B | CUDA | 1 | pp1024 | 295.37 ± 1.66 | | llama 7B Q2_K - Medium | 2.63 GiB | 6.74 B | CUDA | 1 | tg512 | 8.10 ± 0.21 | build: becade5d (4819) === ベンチマーク結果 === 実行コマンド: ./build/bin/llama-bench -m models/ELYZA-japanese-Llama-2-7b-q2_K.gguf -p 1024 -n 512 -ngl 1 -b 2048 -r 3 ---------------------------------- プロンプト処理時間:295.37 ms トークン生成速度 :8.10 トークン/秒 最初のトークン遅延:418.82 ms
他の量子化モデルもダウンロードして比較するとより興味深い結果が得られますね。
$ ./llama-bench-plus.sh ./build/bin/llama-bench models/ELYZA-japanese-Llama-2-7b-q4_K_M.gguf ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce GTX 1070 with Max-Q Design, compute capability 6.1, VMM: yes | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | ------------: | -------------------: | | llama 7B Q4_K - Medium | 3.80 GiB | 6.74 B | CUDA | 1 | pp1024 | 300.09 ± 2.14 | | llama 7B Q4_K - Medium | 3.80 GiB | 6.74 B | CUDA | 1 | tg512 | 6.48 ± 0.02 | build: becade5d (4819) === ベンチマーク結果 === 実行コマンド: ./build/bin/llama-bench -m models/ELYZA-japanese-Llama-2-7b-q4_K_M.gguf -p 1024 -n 512 -ngl 1 -b 2048 -r 3 ---------------------------------- プロンプト処理時間:300.09 ms トークン生成速度 :6.48 トークン/秒 最初のトークン遅延:454.41 ms $ ./llama-bench-plus.sh ./build/bin/llama-bench models/ELYZA-japanese-Llama-2-7b-q5_K_M.gguf ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce GTX 1070 with Max-Q Design, compute capability 6.1, VMM: yes | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | ------------: | -------------------: | | llama 7B Q5_K - Medium | 4.45 GiB | 6.74 B | CUDA | 1 | pp1024 | 280.07 ± 3.08 | | llama 7B Q5_K - Medium | 4.45 GiB | 6.74 B | CUDA | 1 | tg512 | 5.48 ± 0.09 | build: becade5d (4819) === ベンチマーク結果 === 実行コマンド: ./build/bin/llama-bench -m models/ELYZA-japanese-Llama-2-7b-q5_K_M.gguf -p 1024 -n 512 -ngl 1 -b 2048 -r 3 ---------------------------------- プロンプト処理時間:280.07 ms トークン生成速度 :5.48 トークン/秒 最初のトークン遅延:462.55 ms
6. ベンチマーク結果の見方
テスト結果をみてみると…
- プロンプト処理時間(pp1024) … モデルがプロンプトを処理する時間(ミリ秒)- 低いほど良い
- トークン生成速度(tg512) … 1秒間に生成できるトークン数(高いほど良い)
- 最初のトークン遅延 … ユーザーが応答を得始めるまでの時間(低いほど良い)
7. 結果を比較してみよう
以下は、GeForce GTX 1070 with Max-Q Design(ノートPC向けGPU)でのベンチマーク結果の例です。
q2_K量子化モデル
q4_K_M量子化モデル
q5_K_M量子化モデル
グラフ化するとこんな感じになりました。


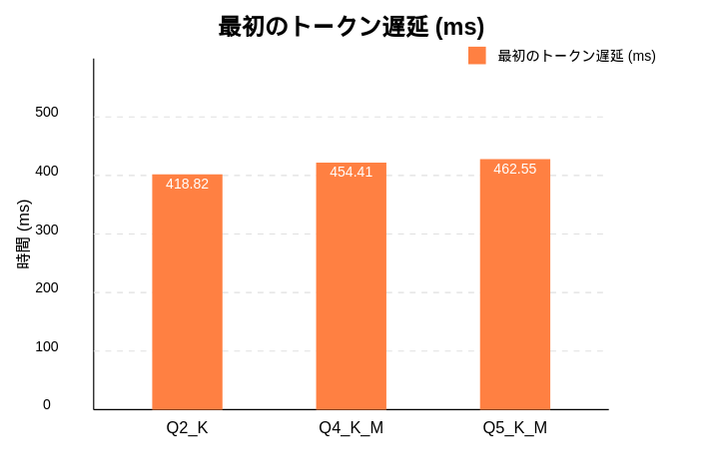
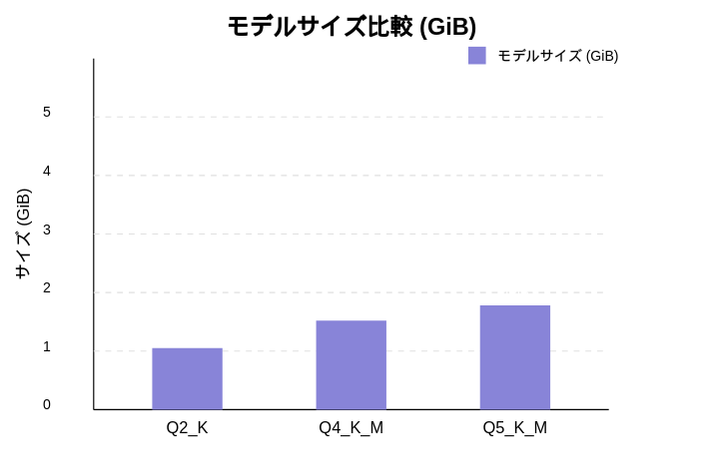
量子化レベルが高い(より精度が高い)モデルほどトークン生成速度は低下するみたいです。逆に考えていました。
この結果をCluade3.7に質問してみたところ以下の様にまとめてくれました。

能力にもっとも関係のあるトークン生成速度については、以下のように評価をしているようでした。
GeForce GTX 1070 with Max-Q Designは入門レベルだったか…🥲🥲🥲
8. まとめ
llama.cppを使ったベンチマークは、自分のGPUがLLMをどれだけ効率よく動かせるかを知るための簡単な方法です。この指標をもとにして、少し旧型のGPU付きのPCでもkの指標をもとにLLMのモデルや量子化モデルを選ぶことで試すレベルの速度でLLM動かすことが出来ます。
今回はELYZA-japanese-Llama-2-7bの量子化モデルを使用していますが、もっといいモデルを選ぶのがいいでしょう。ぜひお手持ちのGPUでテストしてみて、結果をSNSで共有してください。(次のGPU購入のみんなへのヒントになりますし🙇)
ちなみに以下のTanuki-8B-dpo-v1.0-Q8_0.ggufとTanuki-8B-dpo-v1.0の量子化モデルを使用すると以下のようになりました。さすがにトークン生成が遅いので実用性は難しい印象でした。
$ huggingface-cli download team-hatakeyama-phase2/Tanuki-8B-dpo-v1.0-GGUF --local-dir ./models --include "Tanuki-8B-dpo-v1.0-Q8_0.gguf" $ ./llama-bench-plus.sh ./build/bin/llama-bench models/Tanuki-8B-dpo-v1.0-Q8_0.gguf ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce GTX 1070 with Max-Q Design, compute capability 6.1, VMM: yes | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | ------------: | -------------------: | | llama 8B Q8_0 | 7.43 GiB | 7.51 B | CUDA | 1 | pp1024 | 222.05 ± 1.44 | | llama 8B Q8_0 | 7.43 GiB | 7.51 B | CUDA | 1 | tg512 | 2.36 ± 0.01 | build: becade5d (4819) === ベンチマーク結果 === 実行コマンド: ./build/bin/llama-bench -m models/Tanuki-8B-dpo-v1.0-Q8_0.gguf -p 1024 -n 512 -ngl 1 -b 2048 -r 3 ---------------------------------- プロンプト処理時間:222.05 ms トークン生成速度 :2.36 トークン/秒 最初のトークン遅延:645.77 ms $ huggingface-cli download team-hatakeyama-phase2/Tanuki-8B-dpo-v1.0-GGUF --local-dir ./models --include "Tanuki-8B-dpo-v1.0-Q6_K.gguf" $ ./llama-bench-plus.sh ./build/bin/llama-bench models/Tanuki-8B-dpo-v1.0-Q6_K.gguf ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA GeForce GTX 1070 with Max-Q Design, compute capability 6.1, VMM: yes | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | ------------: | -------------------: | | llama 8B Q6_K | 5.74 GiB | 7.51 B | CUDA | 1 | pp1024 | 266.87 ± 1.03 | | llama 8B Q6_K | 5.74 GiB | 7.51 B | CUDA | 1 | tg512 | 4.79 ± 0.03 | build: becade5d (4819) === ベンチマーク結果 === 実行コマンド: ./build/bin/llama-bench -m models/Tanuki-8B-dpo-v1.0-Q6_K.gguf -p 1024 -n 512 -ngl 1 -b 2048 -r 3 ---------------------------------- プロンプト処理時間:266.87 ms トークン生成速度 :4.79 トークン/秒 最初のトークン遅延:475.63 ms