大学の研究で知識関連の構造化を行うことになってきたので、折角なのでNeo4j関連の環境構築をまとめてみました。
今回のゴール
今回は、RDF-starという形式のデータを、グラフデータベースNeo4jを使って取り扱う方法を行います。最終的には、データを入れて、検索し、その結果をNeoDashというツールで分かりやすく可視化(ダッシュボード作成)するところをメインとしています。
いろいろなツールを跨いだ作業になるので、今回はわかりやすくするために絵文字で表現しています。
全てのツールはオープンソースまたは無料で利用できるものを使用します。
ツール
まずは、ツールの役割をイメージしてしていきます。
Neo4j 5.20.0 (Community Edition)→グラフデータベース- 人と人のつながりや、物事の関係性を点(ノード)と線(リレーションシップ)で表現するのが得意なデータベースです。知識やデータを格納する役割を果たします。
neosemantics (n10s) 5.20.0→Neo4jの拡張機能(プラグイン)- セマンティックWeb技術で使われる
RDFというデータ形式を、Neo4jが理解できる形にする存在です。今回は、RDF-starという、情報にメタデータ(信頼度など)を付与できる形式を扱います。
- セマンティックWeb技術で使われる
NeoDash→ダッシュボード作成ツールNeo4jの中にあるデータを、グラフや表の形で見やすく整理するレポート作成ツールです。
Docker/Docker Compose→環境構築ツール- PC上に、今回のハンズオン専用の仮想的な作業環境を構築するツールです。これを使うことで、PCの状態を壊さずに、必要なソフトウェアを一括で準備・起動できます。
環境構成
今回の作業はPC(ホスト環境)と、Dockerの仮想環境(コンテナ環境)で役割が分かれていますが、 ほとんどの処理はDockerの仮想環境で動作します。
- 💻 PC(ホスト環境)
- 🐳 Dockerコンテナ環境
- PCの中に作られる、隔離された仮想的な空間です。
- この環境の中で、
Neo4jやNeoDashが動作します。
- 🌐 Webブラウザ(Chromeを想定)
Dockerコンテナ内で動いているNeo4jやNeoDashにアクセスし、実際にデータを操作したり、ダッシュボードを作ったりするためのユーザーインターフェースです。- Neo4j Browserのアクセス先→http://localhost:7474
- NeoDashのアクセス先→http://localhost:5005
作業するPCの前提条件
DockerとDocker ComposeがPCにインストールされていること。PowerShell(Windows)などのコマンドライン操作が行えること。Google ChromeなどのWebブラウザが使えること。
1. 環境構築(PC上での準備)
このパートのゴールはNeo4jたちが動作する環境を構築し、Dockerのコンテナを起動することです。
1.1 プロジェクトの作業場所を作る
まずは、今回使用するファイルを格納するフォルダを作成します。
💻 PowerShellで実行
# ハンズオン用のフォルダを作成し移動します PS> mkdir neo4j-rdf-star-hands-on PS> cd neo4j-rdf-star-hands-on # Neo4jが必要とするサブフォルダを作成します # data データベースのデータが保存される場所 # plugins 拡張機能(neosemantics)を置く場所 # conf Neo4jの設定ファイルを置く場所 # dashboards NeoDashのデータを保存する場所 PS> mkdir data, plugins, conf, dashboards
1.2 neosemanticsプラグインをダウンロードする
Neo4jがRDF-starのデータを解釈するためのneosemanticsプラグインをダウンロードし、先ほど作成したpluginsフォルダに保存します。
💻 PowerShellで実行
# Webからneosemanticsプラグイン(jarファイル)をダウンロードし、pluginsフォルダに保存します PS> $ProgressPreference = 'SilentlyContinue' PS> Invoke-WebRequest -Uri "https://github.com/neo4j-labs/neosemantics/releases/download/5.20.0/neosemantics-5.20.0.jar" -OutFile "plugins/neosemantics-5.20.0.jar"
プラグインのダウンロード

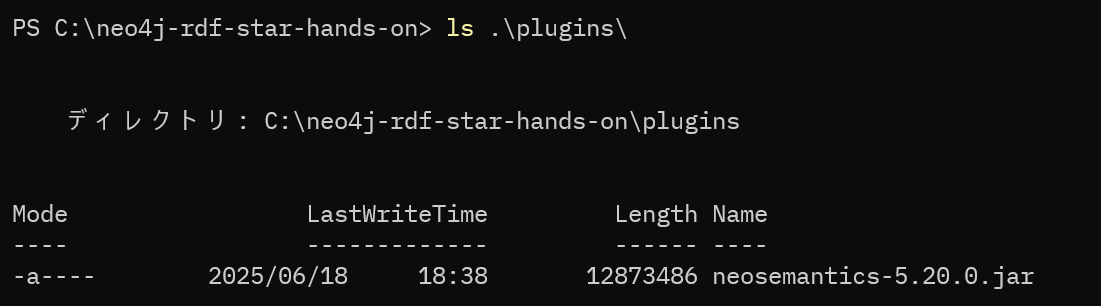
# pluginsフォルダの中にファイルが正しくダウンロードされたか確認します PS> ls plugins
プラグインにファイル名が表示されればOK
1.3 Docker Compose用のファイルを作る
続いて、Neo4jとNeoDashの起動時の設定をする設計書となるdocker-compose.ymlファイルを作成します。
💻 PowerShellでファイルを編集
docker-compose.ymlを以下のように作成
services: # Neo4j database service neo4j: image: neo4j:5.20.0-community container_name: neo4j-community ports: - "7474:7474" # ブラウザ - "7687:7687" # Bolt volumes: - ./data:/data - ./plugins:/plugins - ./conf:/conf environment: - NEO4J_AUTH=neo4j/password - NEO4J_dbms_unmanaged__extension__classes=n10s.endpoint=/rdf - NEO4J_dbms_security_procedures_unrestricted=n10s.* - NEO4J_PLUGINS=["n10s"] restart: unless-stopped # NeoDash dashboard service neodash: image: neo4jlabs/neodash:latest container_name: neodash ports: - "5005:5005" depends_on: - neo4j restart: unless-stopped
これは以下のような動作となります。
docker-compose.yml のざっくり説明
※Neo4jの設定 【サービス】 イメージ : neo4j:5.20.0-community ポート公開 : 7474 (HTTP/Browser), 7687 (Bolt) 【ボリューム】 ./data, ./plugins, ./conf をコンテナ側へマウント 【環境変数】 NEO4J_AUTH=neo4j/password → 初期ログイン資格情報 dbms.unmanaged_extension_classes と dbms.security_procedures_unrestricted を 環境変数用の書式で指定し、neosemantics (n10s) を有効化 NEO4J_PLUGINS=["n10s"] → プラグイン自動読み込み 【その他】 restart: unless-stopped → 手動停止しない限り自動再起動 ※neodash(Neo4jのダッシュボード)の設定 【サービス】 イメージ : neo4jlabs/neodash:latest ポート公開 : 5005 depends_on: neo4j → Neo4j コンテナ起動後に立ち上げ 【その他】 restart: unless-stopped → 手動停止しない限り自動再起動
1.4 環境を起動する
準備は整ったのでdocker-compose.ymlを使ってDockerに環境を立ち上げてもらいましょう!
まずはPC上にDockerが立ち上がっていることを確認します。

💻 PowerShellで実行
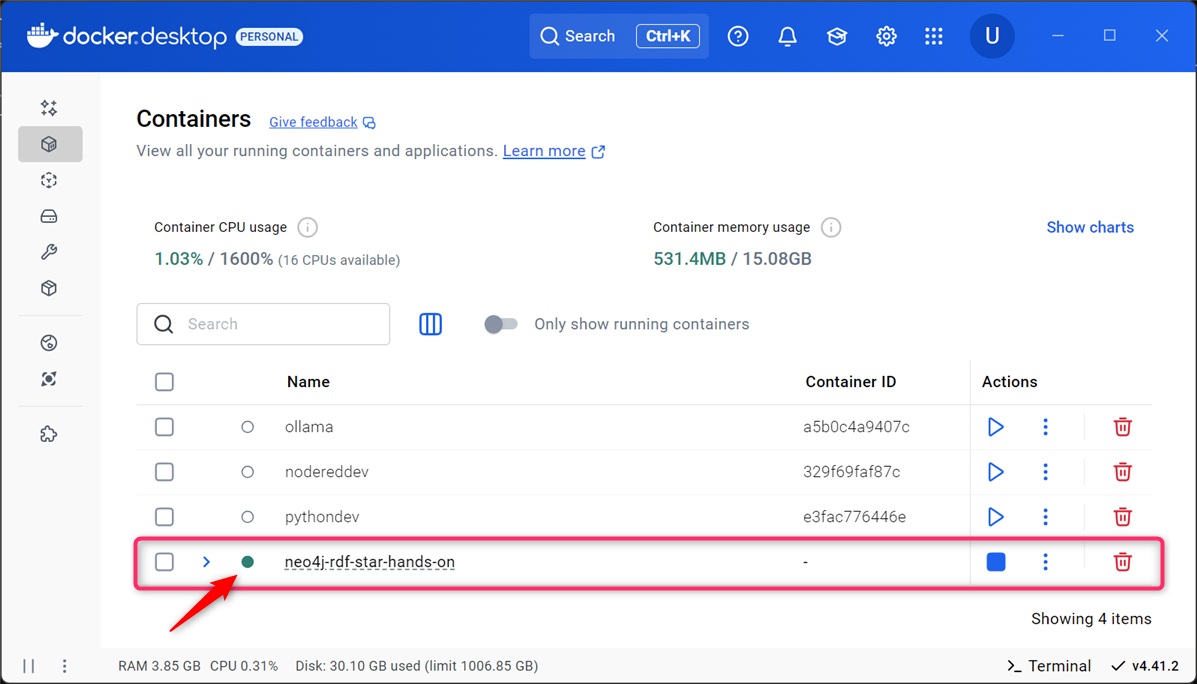
# Docker Composeを使って、バックグラウンドで環境を起動します (-dオプション) PS> docker-compose up -d # 2つのコンテナ(neo4j, neodash)が正常に起動したか確認します PS> docker-compose ps
StateがUpになっていれば成功

Docker Desktopの状態
念のため、それぞれのサービスのログを見て、完全に準備が整ったことを確認します。
💻 PowerShellで実行
# Neo4jのログから "Remote interface available" という文字を探します PS> docker-compose logs neo4j | findstr "Remote interface available" # NeoDashのログから "ready" という文字を探します PS> docker-compose logs neodash | findstr "ready"

これらのメッセージが表示されていれば『環境構築』は無事に完了です!
2. ブラウザでアクセスする
起動したNeo4jとNeoDashに、Webブラウザから無事にアクセスできることを確認します。
🌐 ブラウザで以下にアクセス
1. Neo4j Browserにログイン
- URL → http://localhost:7474 を開きます。
- ログイン画面が表示されたら、以下のように入力します。
- Connect ボタンをクリックし、クエリを入力する画面が表示されれば成功です!
2. NeoDashに接続
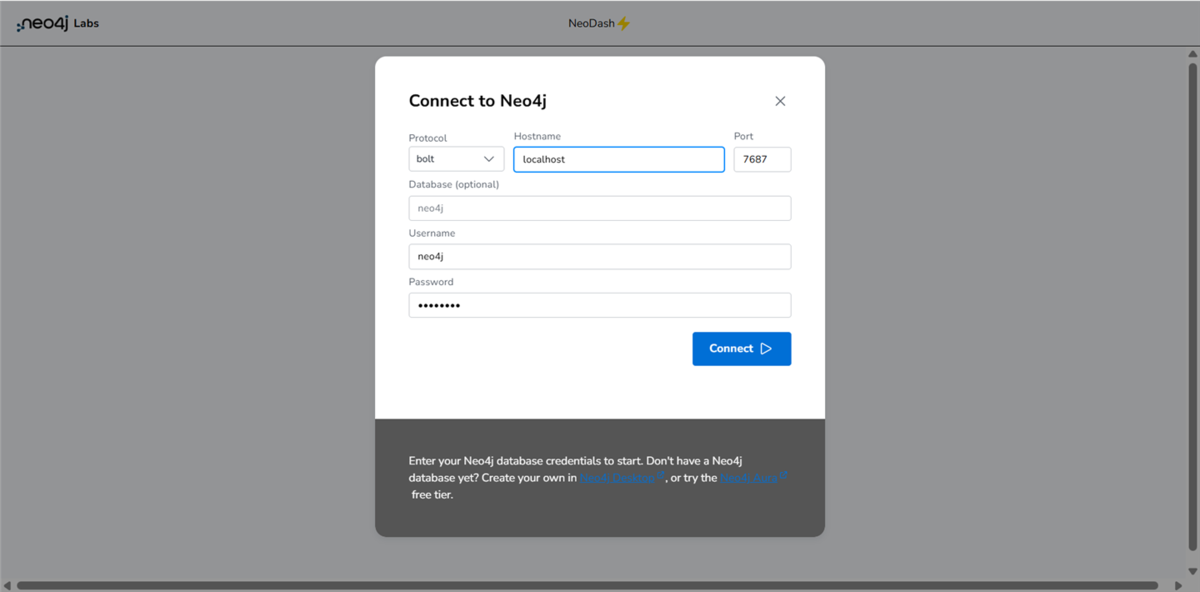
- URL: http://localhost:5005 を開きます。
- ダッシュボードの画面が表示されます。まず、
Neo4jデータベースへの接続設定を行います。 - 画面の【New Dashboard】ボタンをクリックし、接続設定画面を開きます。
- 以下のように入力します。
- Protocol: bolt
- Host: localhost
- Port: 7687
- Username: neo4j
- Password: password
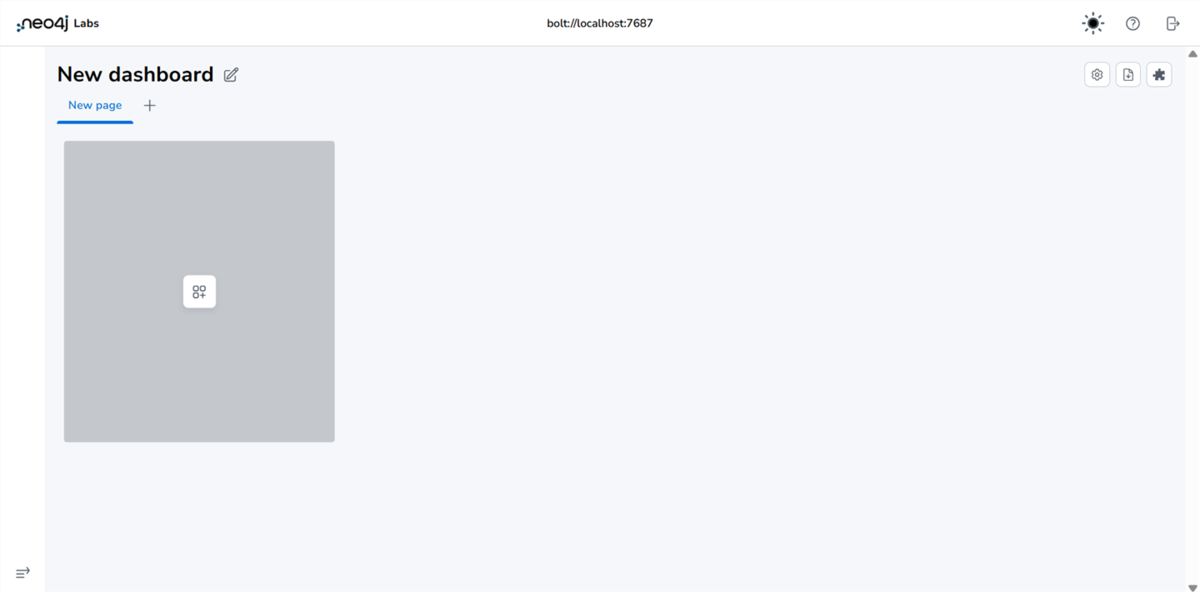
【Connect】ボタンをクリックして、【New Dashboard】の画面が表示されれば成功です!
3. Neo4jの初期設定
Neo4jへRDF-starデータを入れるための準備をします。
🌐 Neo4j Browser (http://localhost:7474) でNeo4jに直接命令を送るための言語であるCypher(サイファー)を使用します。
3.1 プラグインが正しく認識されているか確認
先ほど設定をしたNeo4jのneosemanticsプラグインが、Neo4jにちゃんと認識されているかを確認します。
⚠️修正点
Neo4j 5.x系列ではCALL dbms.procedures()は廃止され、SHOW PROCEDURESコマンドへ変更されています。
地味にハマりました🥲
以下のクエリを入力して、【▶️】ボタンをクリックします。
// 修正:Neo4j 5.x用の新しい構文を使用します // 'n10s'で始まるものだけをフィルタリング // たくさんあるので、最初の10件だけ表示 SHOW PROCEDURES YIELD name, signature, description WHERE name STARTS WITH 'n10s' RETURN name, signature ORDER BY name LIMIT 10;
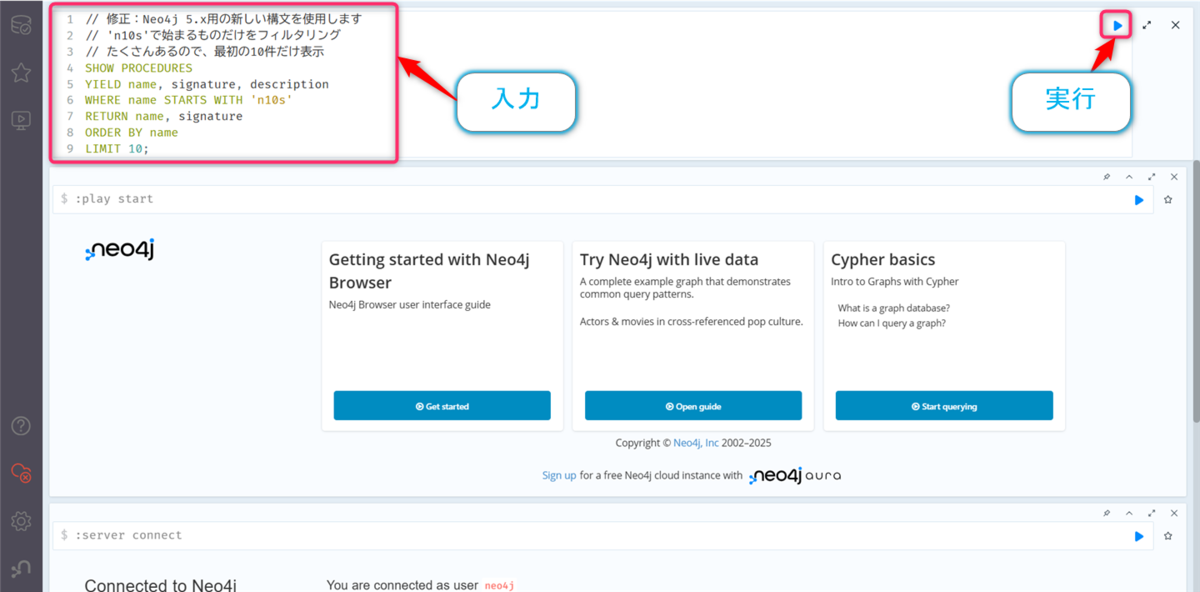
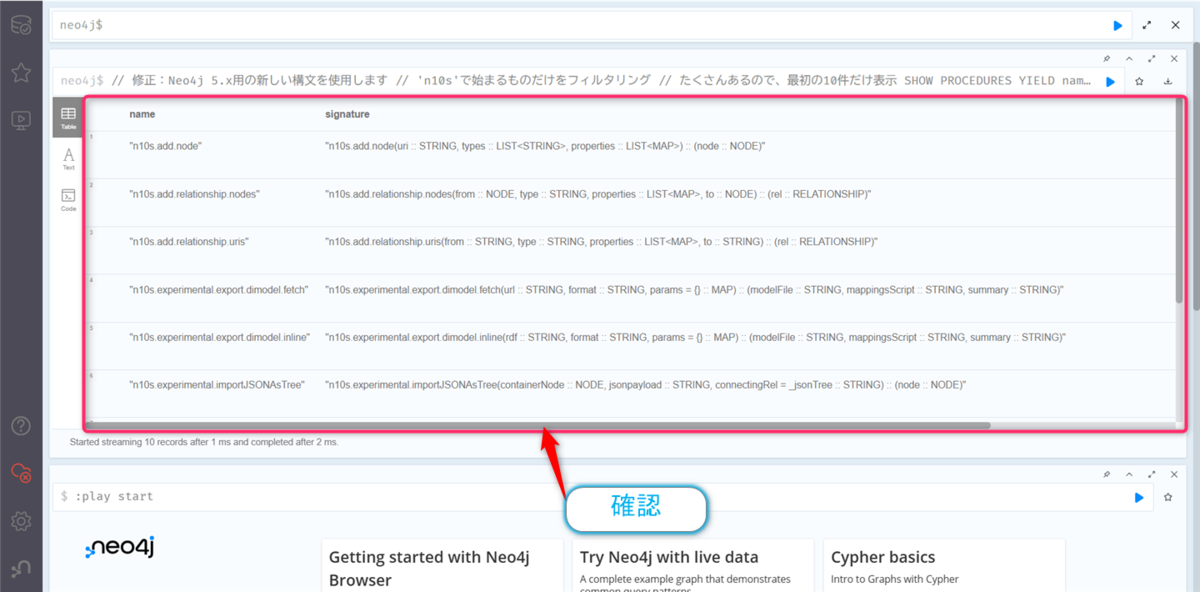
n10s.add.nodeなどの名前がたくさん表示されれば、プラグインは正常に動作しています。
3.2 グラフの取り扱いルールを設定
次に、RDFデータをNeo4jのグラフ形式に変換するときの、細かいルールを設定していきます。
以下のクエリを入力して、【▶️】ボタンをクリックします。
// neosemanticsの初期設定を行います
CALL n10s.graphconfig.init({
handleVocabUris: "MAP", // (解説) URIの末尾をノードのプロパティとして扱う設定
handleMultival: "ARRAY" // (解説) 同じプロパティに複数の値がある場合、配列として扱う設定
});
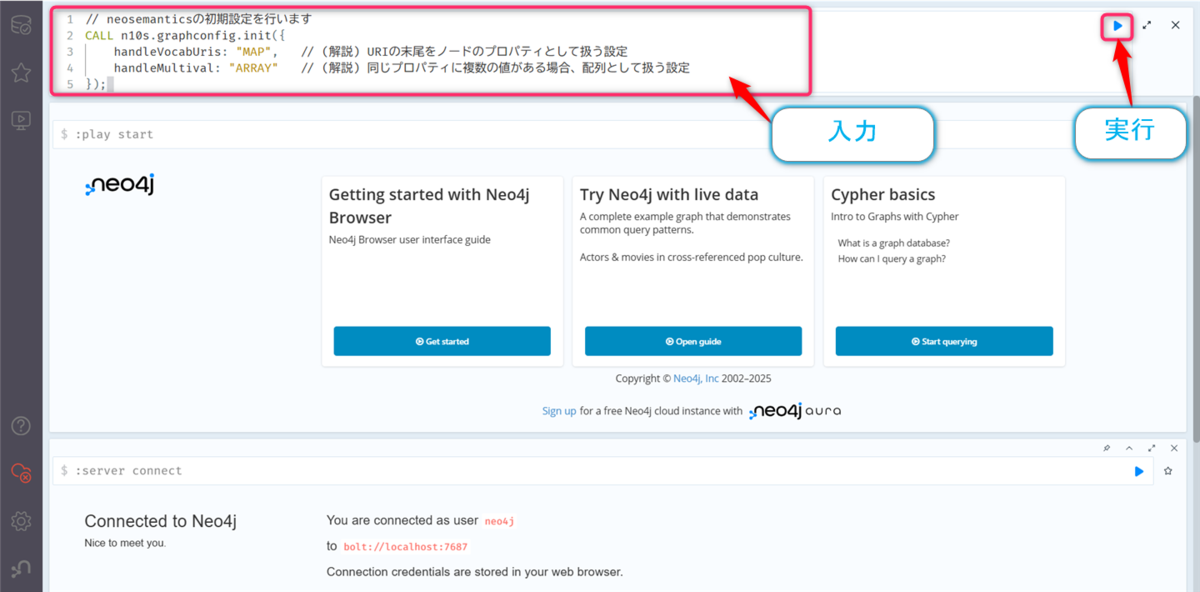
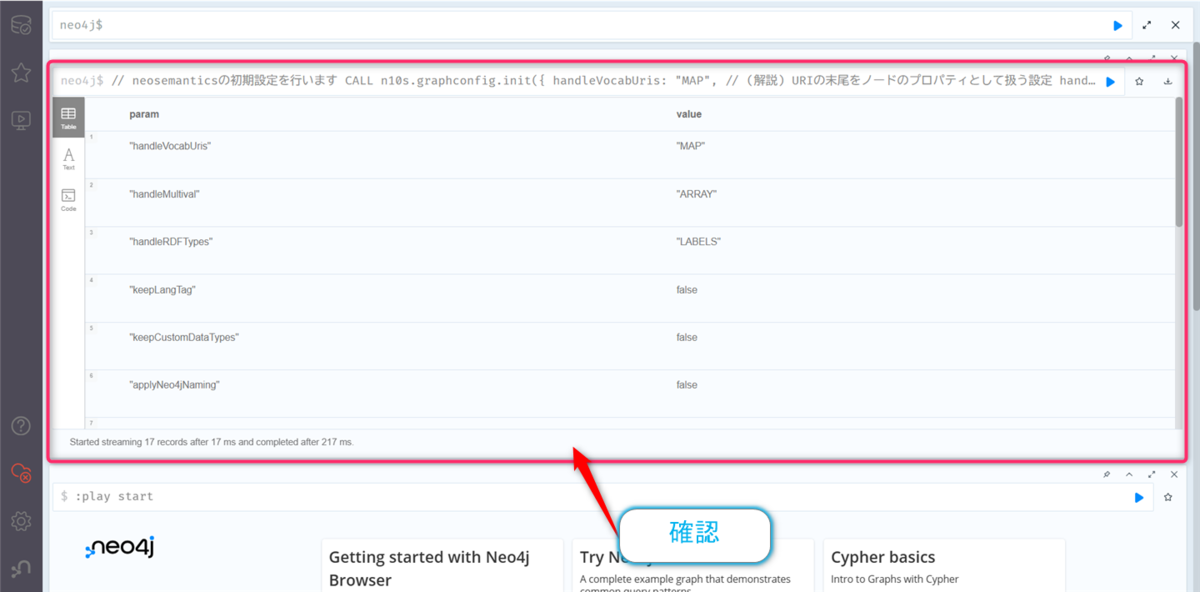
実行結果の値が表示されれば成功です。これは一度だけ実行すればOKです。
3.3 データの整合性を保つための制約の作成
データベースに同じデータを重複して入れてしまわないように、Resourceというラベルが付いたノードのuriプロパティは、必ずユニーク(唯一)でなければならないというルール(制約)を設定しておきます。
以下のクエリを入力して、【▶️】ボタンをクリックします。
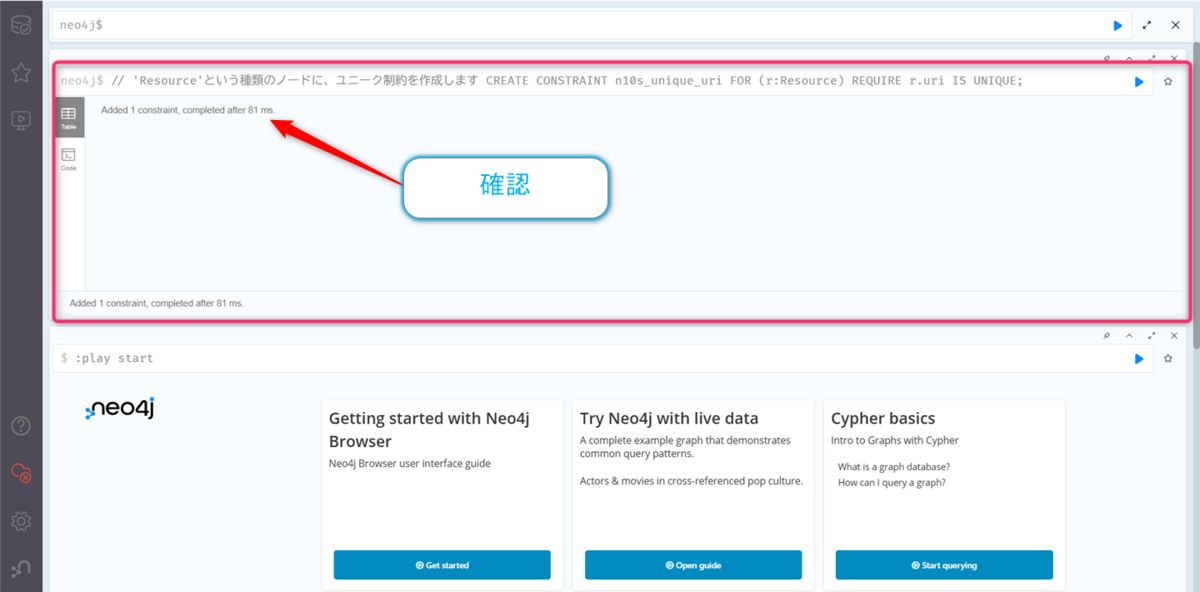
// 'Resource'という種類のノードに、ユニーク制約を作成します CREATE CONSTRAINT n10s_unique_uri FOR (r:Resource) REQUIRE r.uri IS UNIQUE;
Added 1 constraintと表示されれば、設定が追加されました。これで準備は完了です!
4. RDF-starデータの投入
データの入力の練習として「誰がどこに所属しているか」という情報、さらにその情報の「信頼度」や「情報源」をRDF-starデータをNeo4jに投入します。
4.1 サンプルRDF-starデータについて
今回使用するデータは以下のような内容です。<< ... >>で囲まれた部分が、情報にメタデータを紐づけているRDF-starの核となる部分です。
以下はクエリではないので、入力しません。
# Turtle-star形式のデータ
@prefix ex: <http://example.org/> . # ex: という短縮名を定義
# 基本的な情報(トリプル)
ex:研究者A ex:所属 ex:東京大学 .
ex:研究者A ex:専門分野 ex:人工知能 .
ex:研究者B ex:所属 ex:京都大学 .
# 上記の情報に対するメタデータ(アノテーション)
# 「研究者Aが東大所属である」という情報に対して...
<<ex:研究者A ex:所属 ex:東京大学>>
ex:信頼度 0.95 ; # 信頼度は95%
ex:情報源 ex:論文2024 ; # 情報源はこの論文
ex:抽出日時 "2025-06-10" . # この日に抽出した
<<ex:研究者A ex:専門分野 ex:人工知能>> ex:信頼度 0.88 .
<<ex:研究者B ex:所属 ex:京都大学>> ex:信頼度 0.92 .
4.2 RDF-starデータをインポートする
このデータを、neosemanticsの機能を使ってNeo4jにインポートします。
🌐 Neo4j Browserで実行
以下のクエリを入力して、【▶️】ボタンをクリックします。
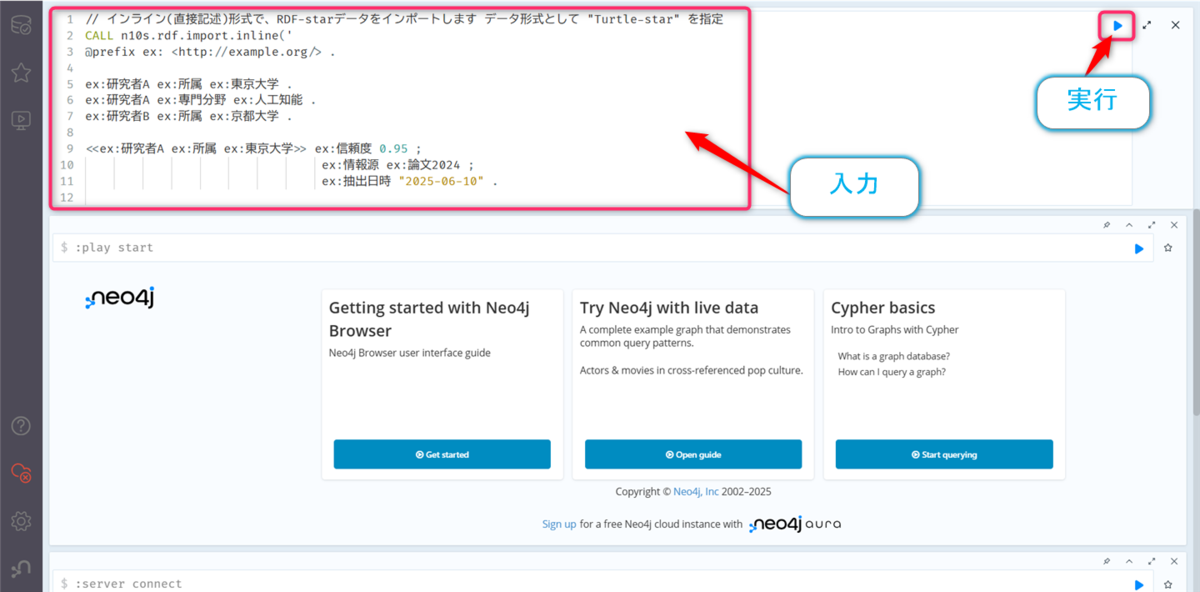
// インライン(直接記述)形式で、RDF-starデータをインポート データ形式として "Turtle-star" を指定
CALL n10s.rdf.import.inline('
@prefix ex: <http://example.org/> .
ex:研究者A ex:所属 ex:東京大学 .
ex:研究者A ex:専門分野 ex:人工知能 .
ex:研究者B ex:所属 ex:京都大学 .
<<ex:研究者A ex:所属 ex:東京大学>> ex:信頼度 0.95 ;
ex:情報源 ex:論文2024 ;
ex:抽出日時 "2025-06-10" .
<<ex:研究者A ex:専門分野 ex:人工知能>> ex:信頼度 0.88 ;
ex:情報源 ex:学会発表 ;
ex:抽出日時 "2025-06-11" .
<<ex:研究者B ex:所属 ex:京都大学>> ex:信頼度 0.92 ;
ex:情報源 ex:公式サイト ;
ex:抽出日時 "2025-06-12" .
', "Turtle-star"); // データ形式として "Turtle-star" を指定
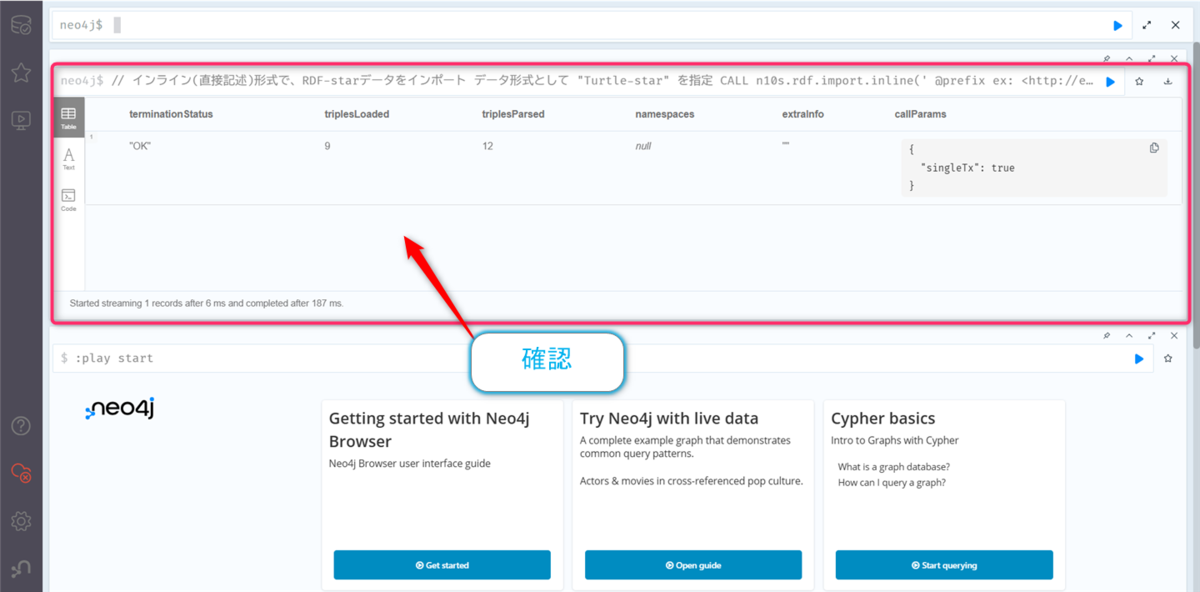
triplesLoaded: 9のように、読み込んだトリプル数が表示されればインポート成功です!
5. 🔍 データの確認と検索
このパートではNeo4jに入ったデータが、意図通りにグラフ構造として格納されているかを確認し、基本的な検索クエリを実行してみます。
🌐 Neo4j Browserで実行
5.1 データがグラフになっているか確認する
インポートしたデータがどのようなグラフになったか、視覚的に確認してみます。
以下のクエリを入力して、【▶️】ボタンをクリックします。
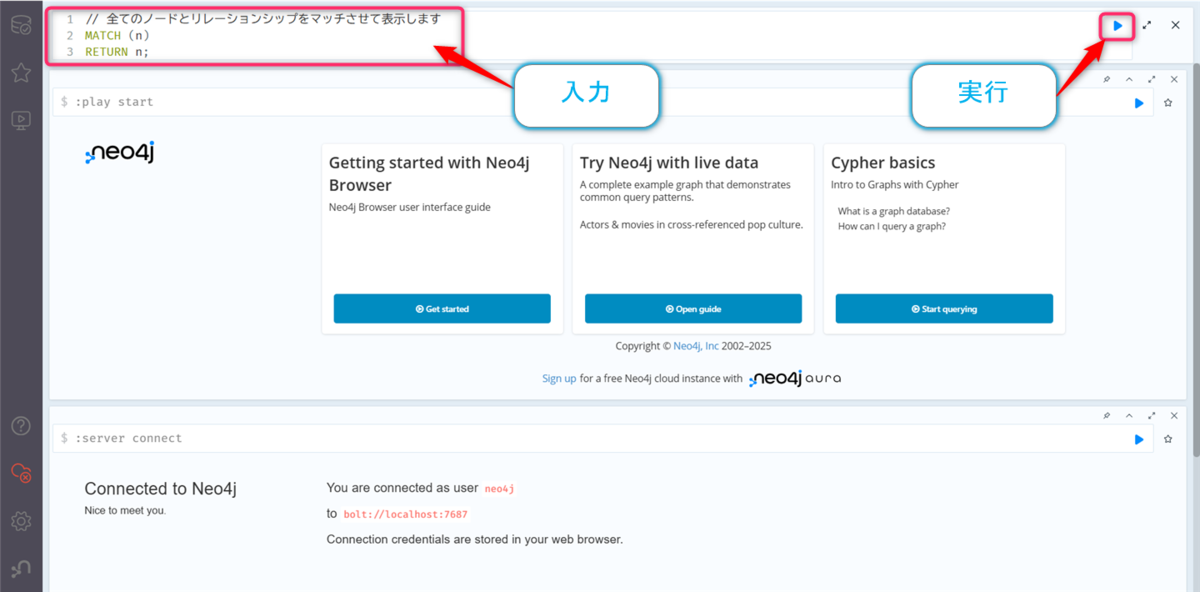
// 全てのノードとリレーションシップをマッチさせて表示します MATCH (n) RETURN n;
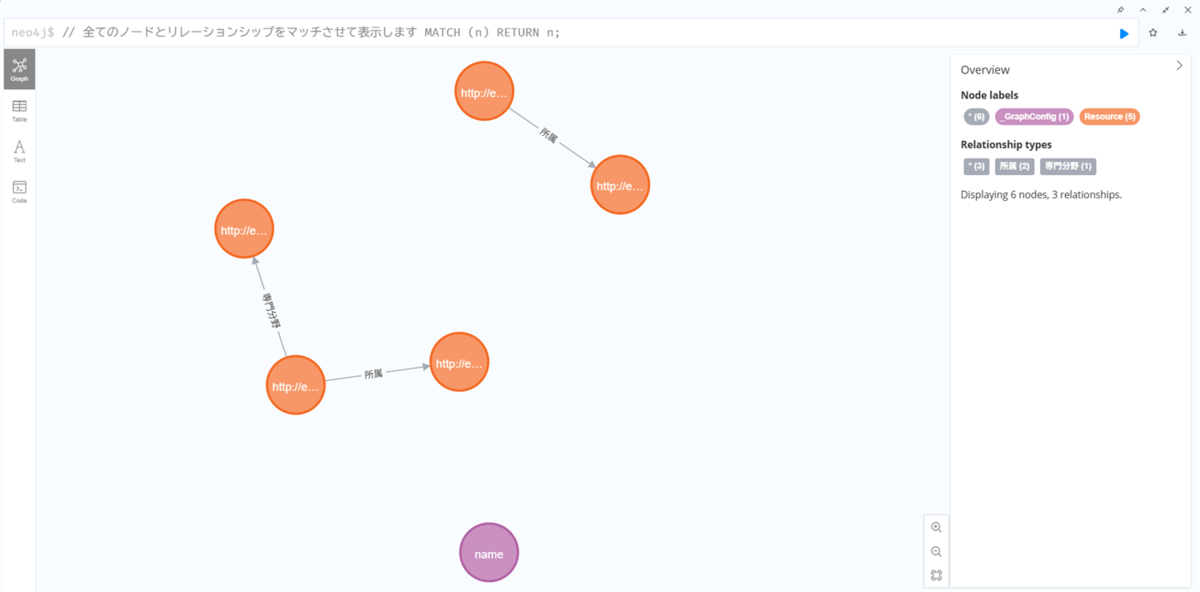
実行後、結果表示の左側のGraphタブをクリックすると、ノード(丸)とリレーションシップ(矢印)で構成されたグラフが表示されるはずです。「研究者A」ノードから「東京大学」ノードへ「所属」という矢印が伸びているのが見えると思います。
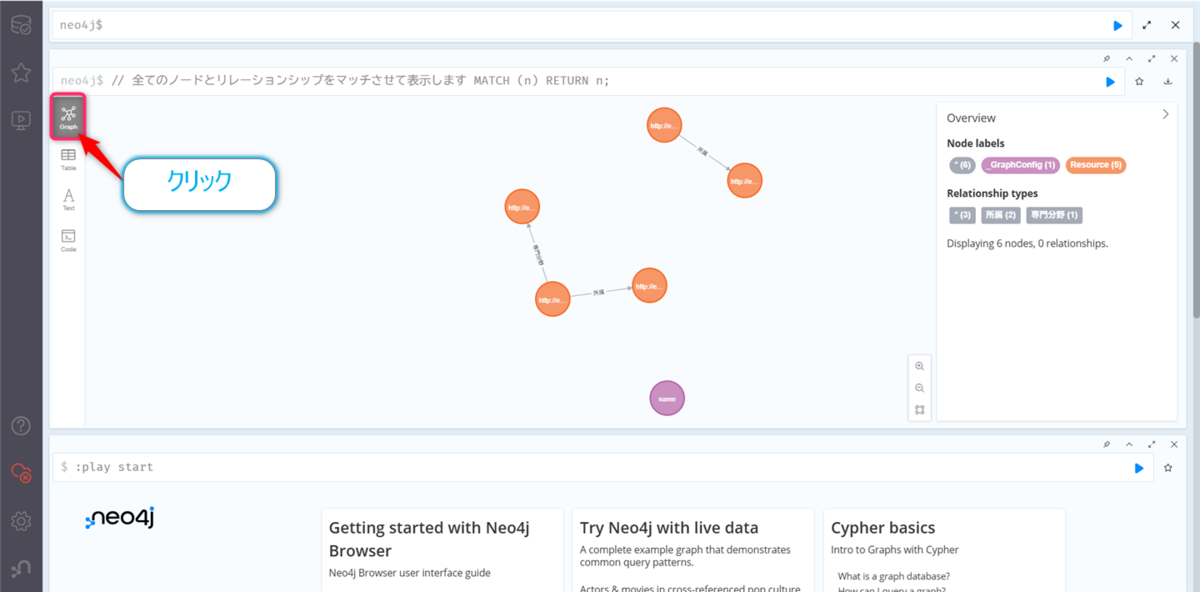
グラフ部分の拡大
5.2 メタデータ(アノテーション)を確認する
RDF-starのメタデータ(信頼度など)は、リレーションシップのプロパティとして格納されています。これを確認してみましょう。
以下のクエリを入力して、【▶️】ボタンをクリックします。
MATCH (s:Resource)-[r]->(o:Resource)
WHERE r.信頼度 IS NOT NULL
RETURN split(s.uri, "/")[-1] AS 研究者,
type(r) AS 関係,
split(o.uri, "/")[-1] AS 所属_専門,
r.信頼度 AS 信頼度,
r.情報源 AS 情報源,
r.抽出日時 AS 抽出日時;

出力 (テーブル形式で表示):
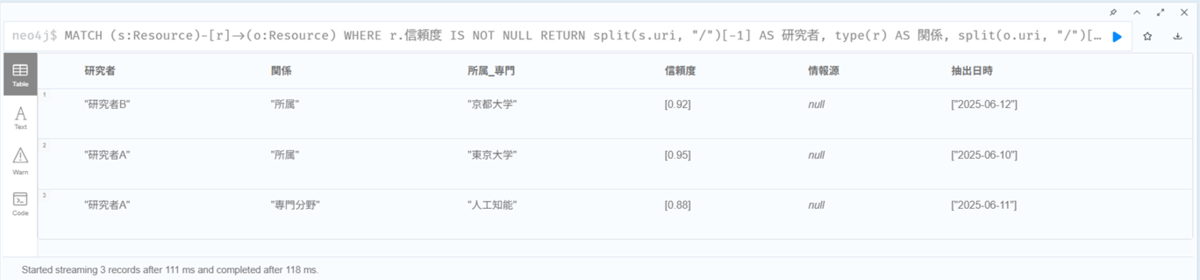

このように、情報の「中身」だけでなく、「その情報の信頼性」が一緒に管理できるのがRDF-starとNeo4jを組み合わせる大きなメリットです。
5.3 条件を指定して検索する
Cypherクエリを使えば、SQLのように柔軟なデータ検索も可能です。
信頼度が0.9以上の情報だけを抽出
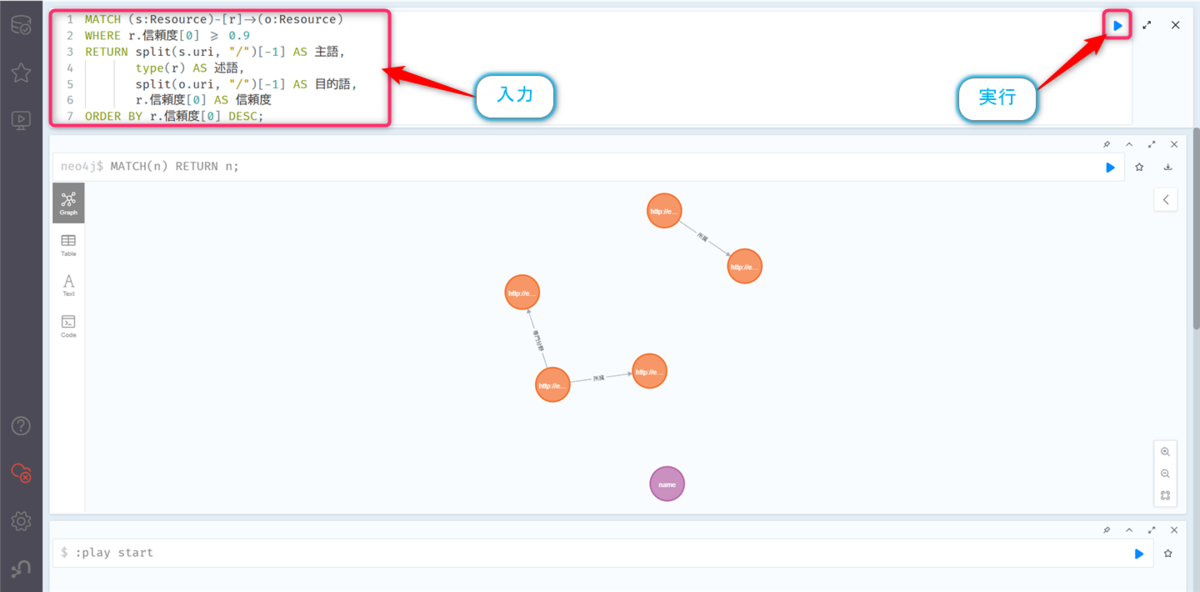
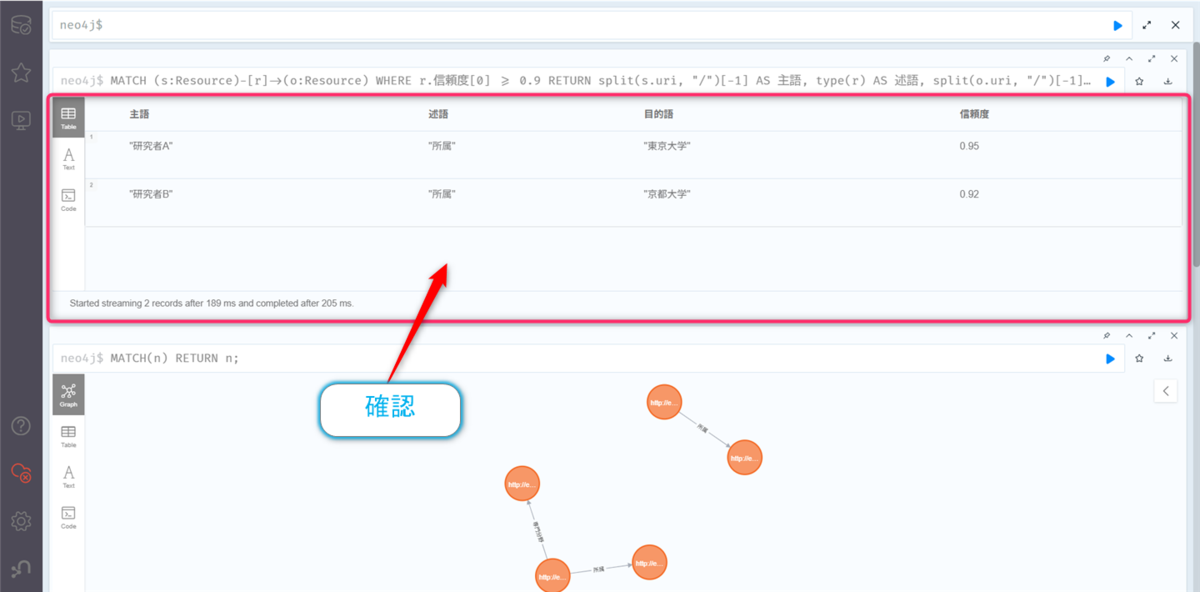
以下のクエリを入力して、【▶️】ボタンをクリックします。
MATCH (s:Resource)-[r]->(o:Resource)
WHERE r.信頼度[0] >= 0.9
RETURN split(s.uri, "/")[-1] AS 主語,
type(r) AS 述語,
split(o.uri, "/")[-1] AS 目的語,
r.信頼度[0] AS 信頼度
ORDER BY r.信頼度[0] DESC;

6. データの更新
このパートでは、一度格納したデータの情報を更新したり、新しいプロパティを追加します。
🌐 Neo4j Browserで実行
6.1 既存のデータを更新する
例えば、情報の精査が進んで信頼度が上がった場合、その値を更新します。
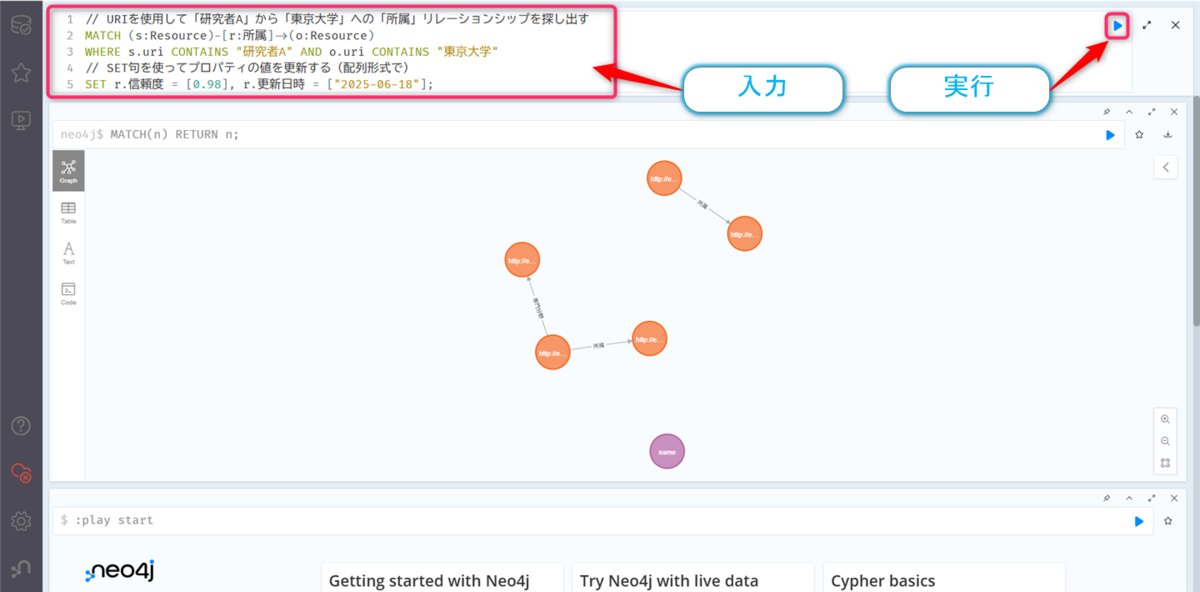
以下のクエリを入力して、【▶️】ボタンをクリックします。
// URIを使用して「研究者A」から「東京大学」への「所属」リレーションシップを探し出す MATCH (s:Resource)-[r:所属]->(o:Resource) WHERE s.uri CONTAINS "研究者A" AND o.uri CONTAINS "東京大学" // SET句を使ってプロパティの値を更新する(配列形式で) SET r.信頼度 = [0.98], r.更新日時 = ["2025-06-18"];
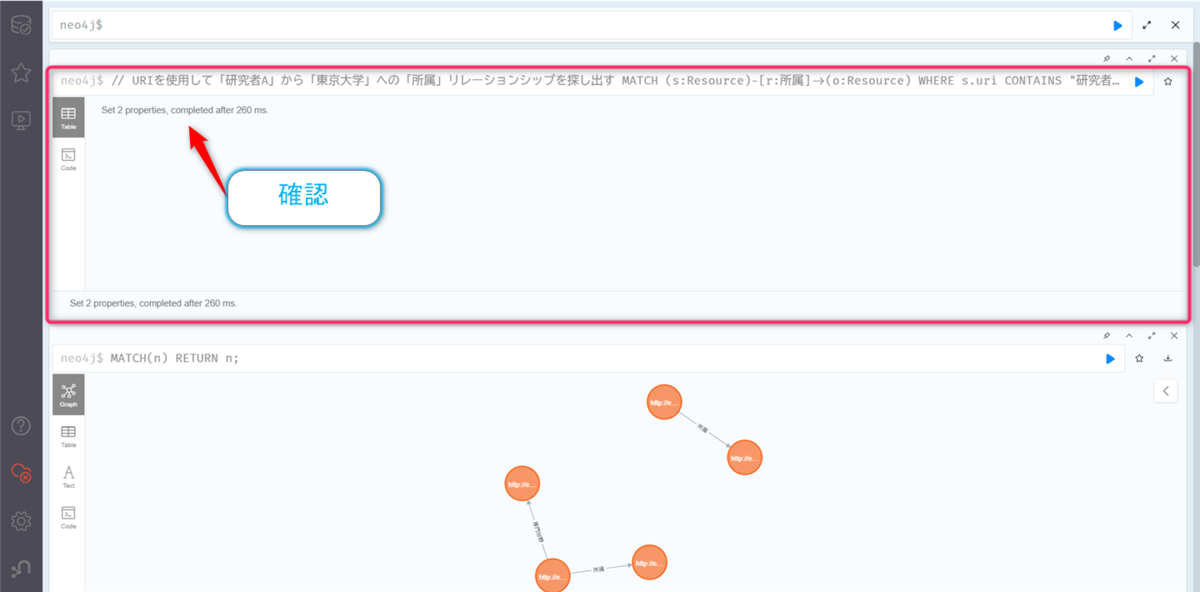
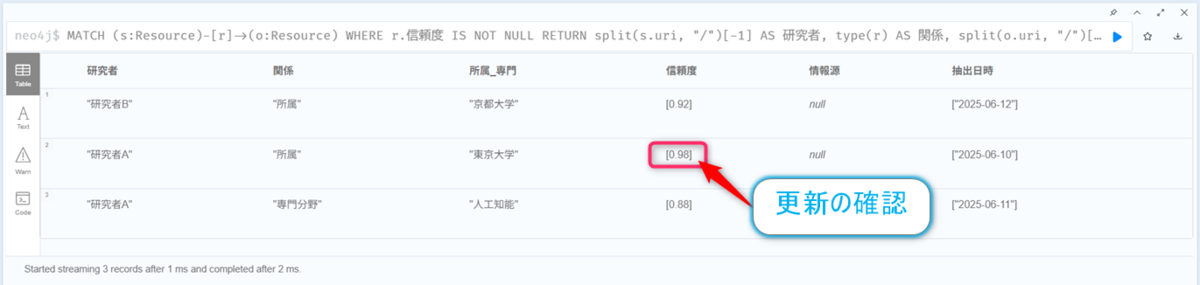
再度、5.のクエリを実行すると、信頼度が更新されていることが確認できます。
6.2 新しいプロパティを追加する
後から新しい管理項目を追加することも簡単です。例えば、「この情報は人間が確認済みか」というフラグを追加してみましょう。
以下のクエリを入力して、【▶️】ボタンをクリックします。
// 抽出日時が"2025-06-10"のリレーションシップを探す(論文2024相当のデータ) MATCH ()-[r]->() WHERE r.抽出日時[0] = "2025-06-10" SET r.確認済み = [true], r.情報源 = ["論文2024"];
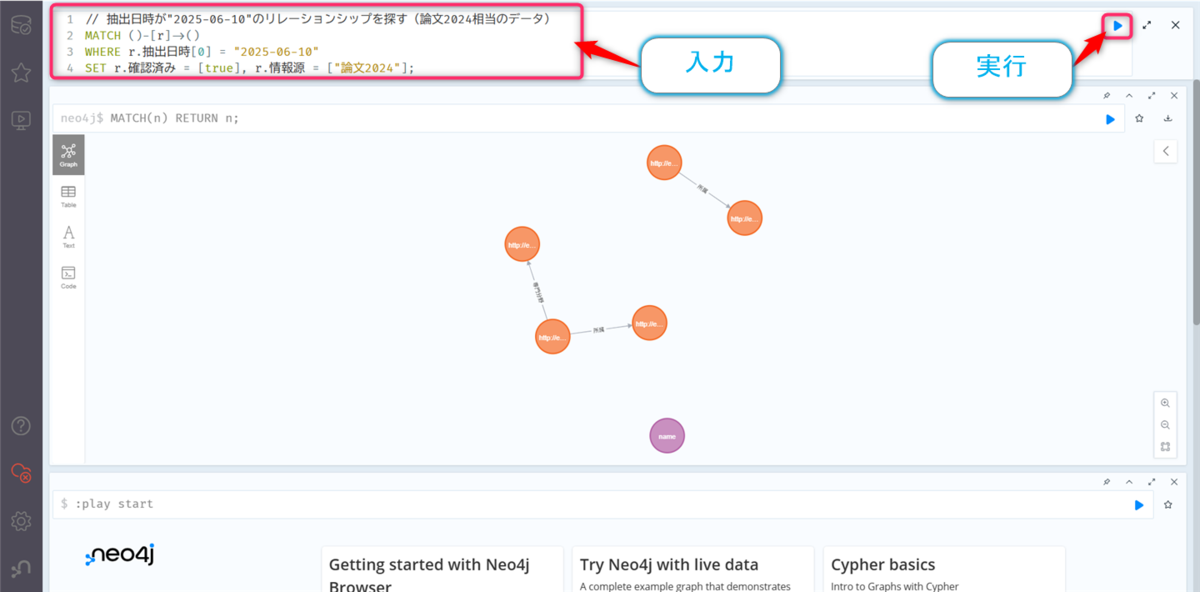
確認用のクエリ
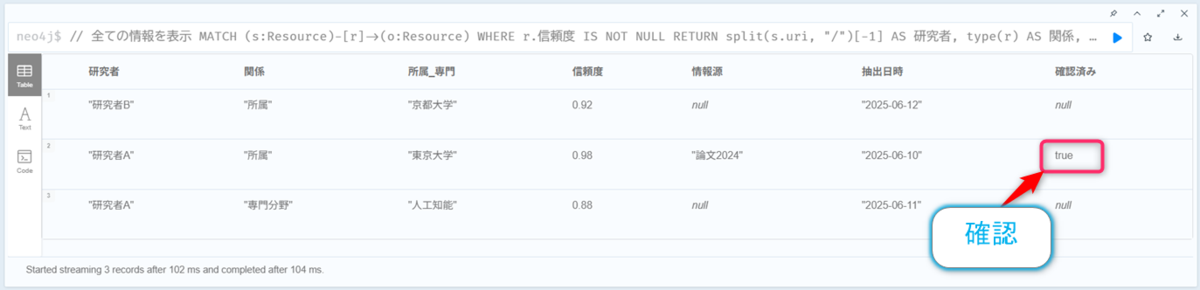
以下のクエリを入力して、【▶️】ボタンをクリックします。
// 全ての情報を表示
MATCH (s:Resource)-[r]->(o:Resource)
WHERE r.信頼度 IS NOT NULL
RETURN split(s.uri, "/")[-1] AS 研究者,
type(r) AS 関係,
split(o.uri, "/")[-1] AS 所属_専門,
r.信頼度[0] AS 信頼度,
r.情報源[0] AS 情報源,
r.抽出日時[0] AS 抽出日時,
r.確認済み[0] AS 確認済み;
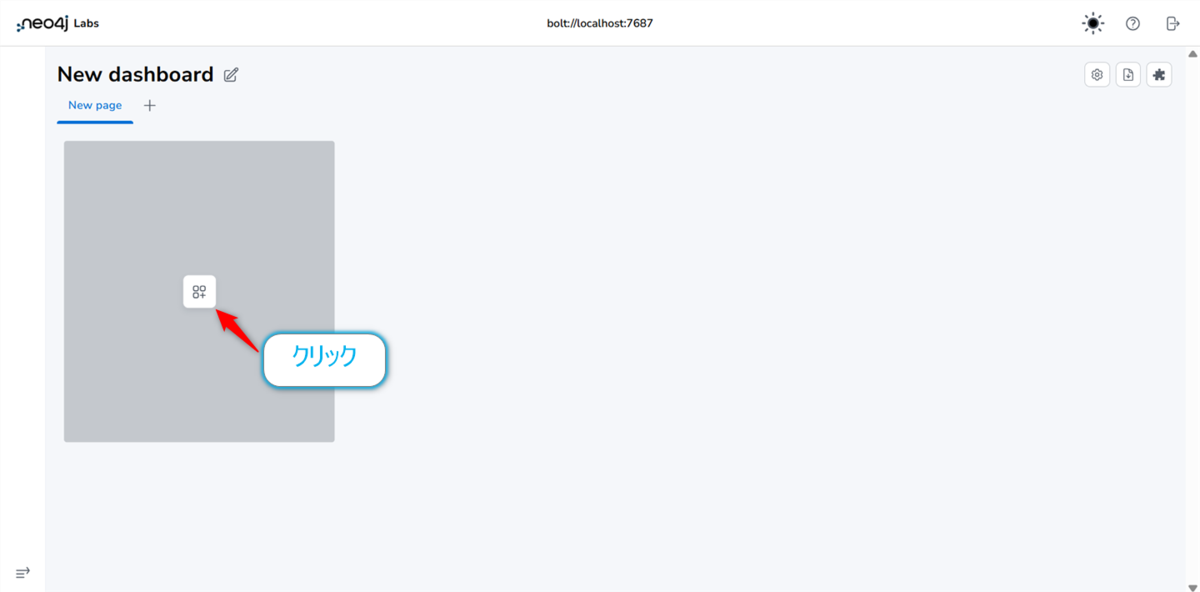
7. 📈 NeoDashでダッシュボードを作る
このパートのゴール: これまでCypherクエリで見てきた結果を、NeoDashを使って分かりやすいダッシュボードにまとめます。
🌐 NeoDash (http://localhost:5005) で作業
- ブラウザでNeoDashを開き、Neo4jデータベースに接続します(
2.で実施済み)。 - 【Add Report】ボタンを押し、様々な種類のレポートを追加していきます。
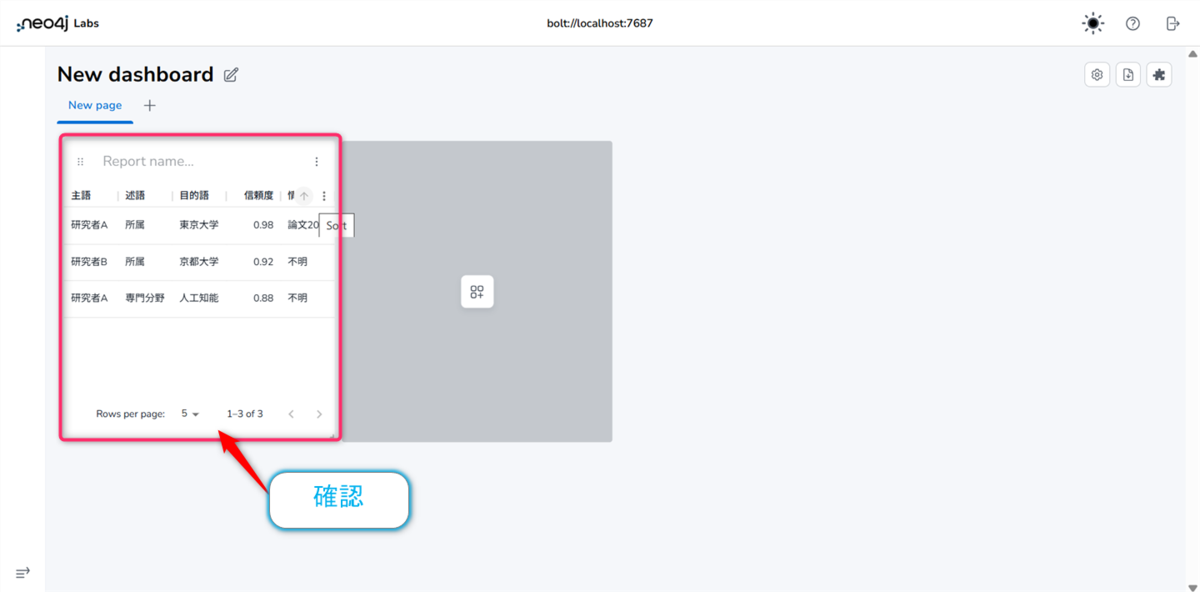
レポート1 データ一覧表 (Table)
- 【Type】のプルダウンをTableに選択します。
- Cypherクエリを入力する欄に、以下のクエリを貼り付けます。
MATCH (s:Resource)-[r]->(o:Resource)
WHERE r.信頼度 IS NOT NULL
RETURN split(s.uri, "/")[-1] as 主語,
type(r) as 述語,
split(o.uri, "/")[-1] as 目的語,
r.信頼度[0] as 信頼度,
COALESCE(r.情報源[0], "不明") as 情報源
ORDER BY r.信頼度[0] DESC;
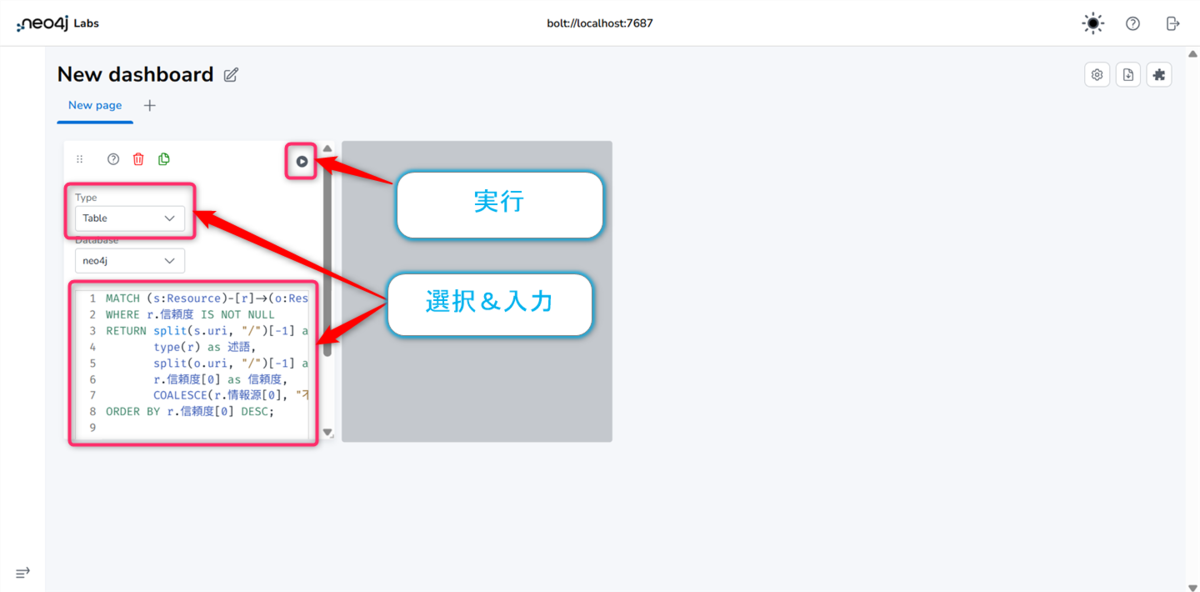
- 自動的に表が生成されます。列名などを調整して見やすくしましょう。
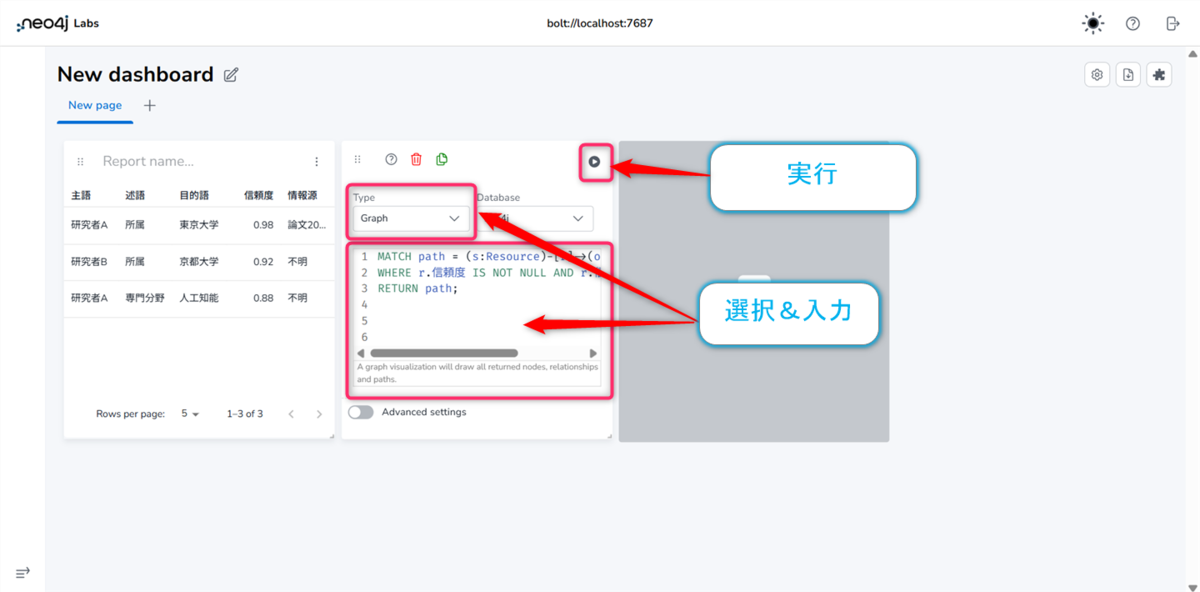
レポート2 関係性のネットワーク図 (Graph)
- Type → Graph を選択します。
- 以下のクエリを貼り付けます。
MATCH path = (s:Resource)-[r]->(o:Resource) WHERE r.信頼度 IS NOT NULL AND r.信頼度[0] >= 0.9 RETURN path;
- 信頼度の高いデータだけがネットワーク図として可視化されます。ノードをドラッグして動かしてみましょう。
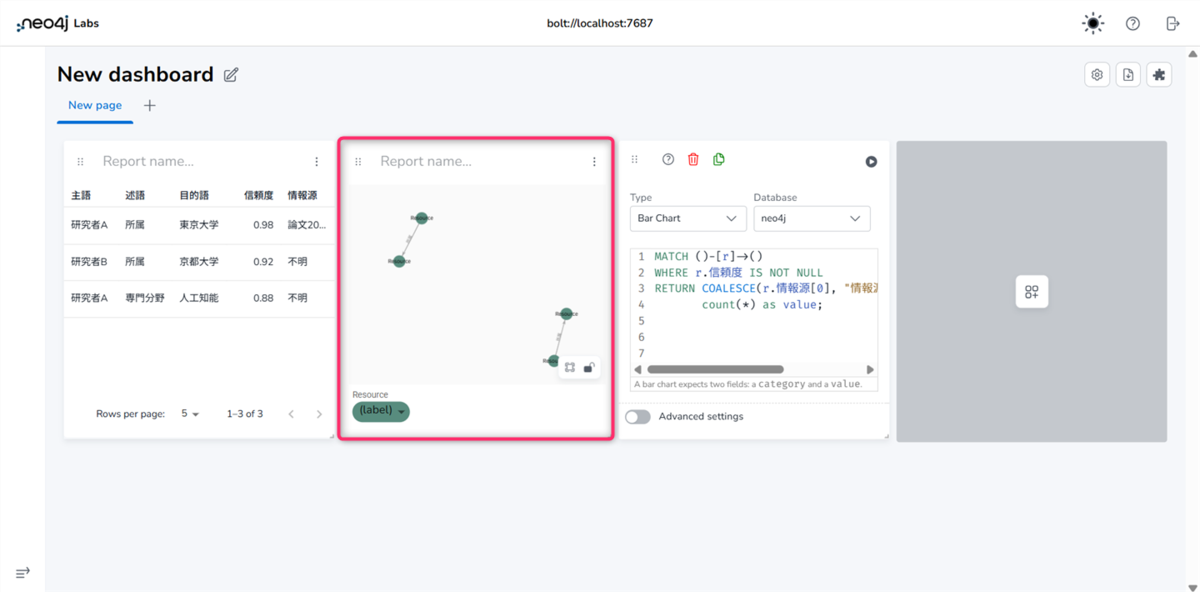
レポート3 情報源別データ数 (Bar Chart)
- 【Type】のプルダウンを【Bar Chart】に選択します。
- 以下のクエリを貼り付けます。
MATCH ()-[r]->()
WHERE r.信頼度 IS NOT NULL
RETURN COALESCE(r.情報源[0], "情報源不明") as category,
count(*) as value;
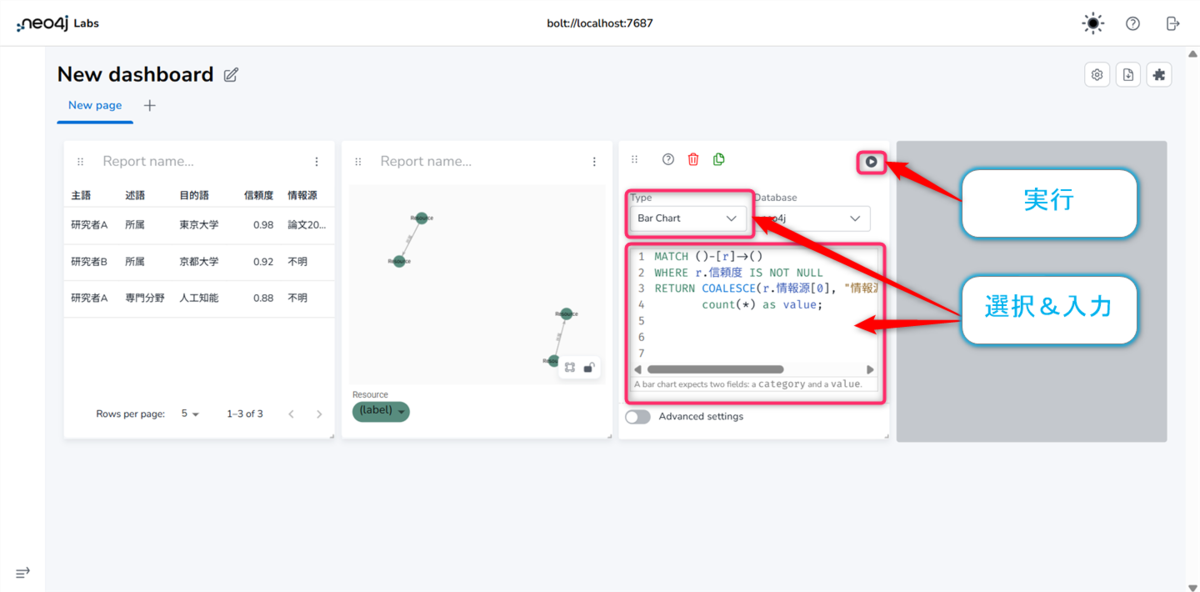
- 情報源ごとのデータ数が棒グラフで表示されます。
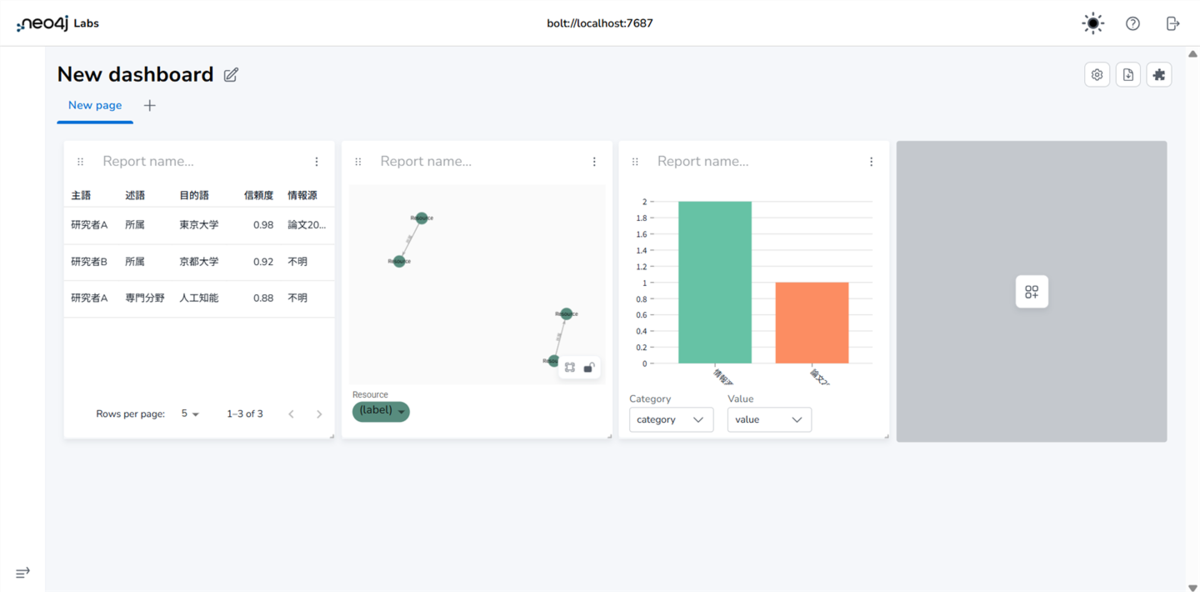
複数のレポートを組み合わせることでダッシュボードが完成します。画面右上の【⚙️(export)】ボタンでダッシュボードを保存できます。
8. 後片付けと管理
ここでは今回使用した環境を安全に停止・削除します。
💻 PowerShellで実行
8.1 環境の停止と再起動
# 環境を一時停止します PS> docker-compose stop # 環境を再開します PS> docker-compose start # 環境を完全に停止します PS> docker-compose down
8.2 環境の完全なクリーンアップ
ハンズオンが完全に終了し、データも不要になった場合は、以下のコマンドでコンテナとデータボリュームをまとめて削除できます。
⚠️ 注意: この操作を実行すると、データベース内のデータが全て消去されます!
# コンテナと、データが保存されていたボリューム(-v)を完全に削除します PS> docker-compose down -v # 作業フォルダごと削除します PS> cd .. PS> Remove-Item -Path "neo4j-rdf-star-hands-on" -Recurse -Force
おわりに
以下のことを実験しました。
- Dockerを使った簡単な環境構築(安定版Neo4j 5.20.0使用)
- neosemanticsプラグインによるRDF-starデータのインポート
- Cypherクエリによる柔軟なデータ検索と集計
- NeoDashを使った直感的なダッシュボード作成
今回扱った技術は、情報の出所や信頼性が重要となるナレッジグラフや、高度な検索システム(RAGなど)の基盤として使用できそうです。(そのつもりでやっているのですが…)
システムとしては動作しましたが、私自身のスキルに不安も残ります🥲