
最近、音声認識の処理を行うプログラムを作成しています。開発・デバッグの際、マイクの前でテーマに沿った話をして、音声認識の確認を行う必要があるのです。内心これがとても面倒だなと思っています。特にテーマなどに全く関心がない場合には、なんにも頭にうかばない😫😫😫
そんなとき、RaspberryPiで音声合成をしたことを思いだしました。WSL環境でもできないかなと思いやってみることにしました。今回の内容は、WSL上に設定したVOICEVOX COREをPythonから利用する方法のまとめとなります。
以前はRaspberryPiにVOICEVOX COREを導入していましたが、今回はWSL環境への差し替えです。おおよその作業の流れは変わっていないと思います。
参考
再掲となりますが、VOICEVOX COREは、無料で高品質な音声合成が行えるソフトウェアで、特にプログラムを使って音声合成を行いたい方にはおすすめです。
今回は、環境設定・インストールとPythonからの簡単な使用例について解説します。
1. VOICEVOX COREとは?
VOICEVOX COREは、オープンソースの音声合成エンジンで、リアルタイムで音声を生成することができます。公式サイトから様々なスタイルの話者をダウンロードして利用できます。
VOICEVOXはアプリ、Editor、Engine、Coreから構成されていますが、その中のCore部分のみを使用しています。コンソール画面で使用できるのでお手軽です。
公式情報、VOICEVOXのシステム構成については以下のリンクを参考にしてください。
2. インストール手順
以下を事前に準備する必要があります。
必要な準備
以下の準備を行います。
- Pythonの仮想環境の準備
- VOICEVOX COREの
.whlファイルのダウンロード - ONNX Runtimeのインストール
- Open JTalk辞書ファイルのダウンロード
詳細は以降で説明していきます。
2-0. Pythonの仮想環境の準備
Pythonのバージョンは3.8以降、pipやvenvも使用できるようにしておいてください。
Ubuntu24.04 LTSではPythonのバージョンが3.10ですが、pipやvenvが使用できないので、apt installコマンドで導入をお願いします。
また、今回はvoicevoxcoreというディレクトリで作業を行っていきます。
# 作業用ディレクトリの作成と移動 $ mkdir voicevoxcore $ cd voicevoxcore # 仮想環境の作成 $ python -m venv venv # 仮想環境の有効化 $ source venv/bin/activate
2-1. VOICEVOX COREの準備と.whlファイルのダウンロード
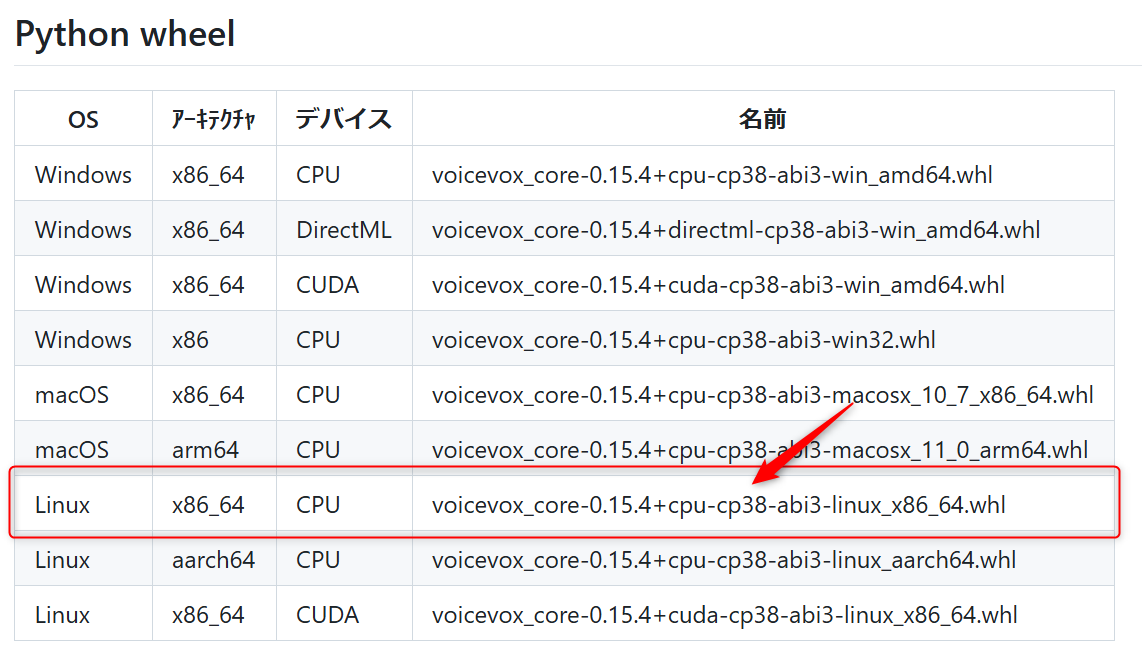
GitHubのリリースページから適切な.whlファイルをダウンロードします。
リポジトリには以下のように記載があるので、バージョン0.15.4を使用します。
現在の main ブランチは工事中なので正しく動かないことがあります。バージョン 0.15.4をご利用ください。
今回はWindows64bitの上のWSLを使用するため、Windows側ではなくLinux側(Linux x86_64 CPU)の.whlを選んでください。また、nvidiaのGPUを搭載したCUDA対応の機器を持っている方はCUDA側の.whlを使用すると幸せになれると思います。
インストール
.whlファイルをダウンロードして以下のコマンドでインストールします。以下コマンドは選択したアーキテクチャに合わせてリンク、ファイル名を変更してください。
※ダウンロードはかなり大きなサイズになります。
$ wget https://github.com/VOICEVOX/voicevox_core/releases/download/0.15.4/voicevox_core-0.15.4+cpu-cp38-abi3-linux_x86_64.whl $ pip install voicevox_core-0.15.4+cpu-cp38-abi3-linux_x86_64.whl
2-2.ONNX Runtimeのインストール
ONNX(Open Neural Network Exchange)は、オープンソースで開発されている機械学習や人工知能のモデルを表現する為の代表的なフォーマットで、その実行環境がONNX Runtimeとなります。
ONNX Runtimeは様々な環境におけるONNXモデルの推論・学習高速化を目的としたオープンソースプロジェクトである。フレームワーク・OS・ハードウェアを問わず単一のRuntime APIを介してONNXモデルを利用できる。
【参考】 https://ja.wikipedia.org/wiki/Open_Neural_Network_Exchange\
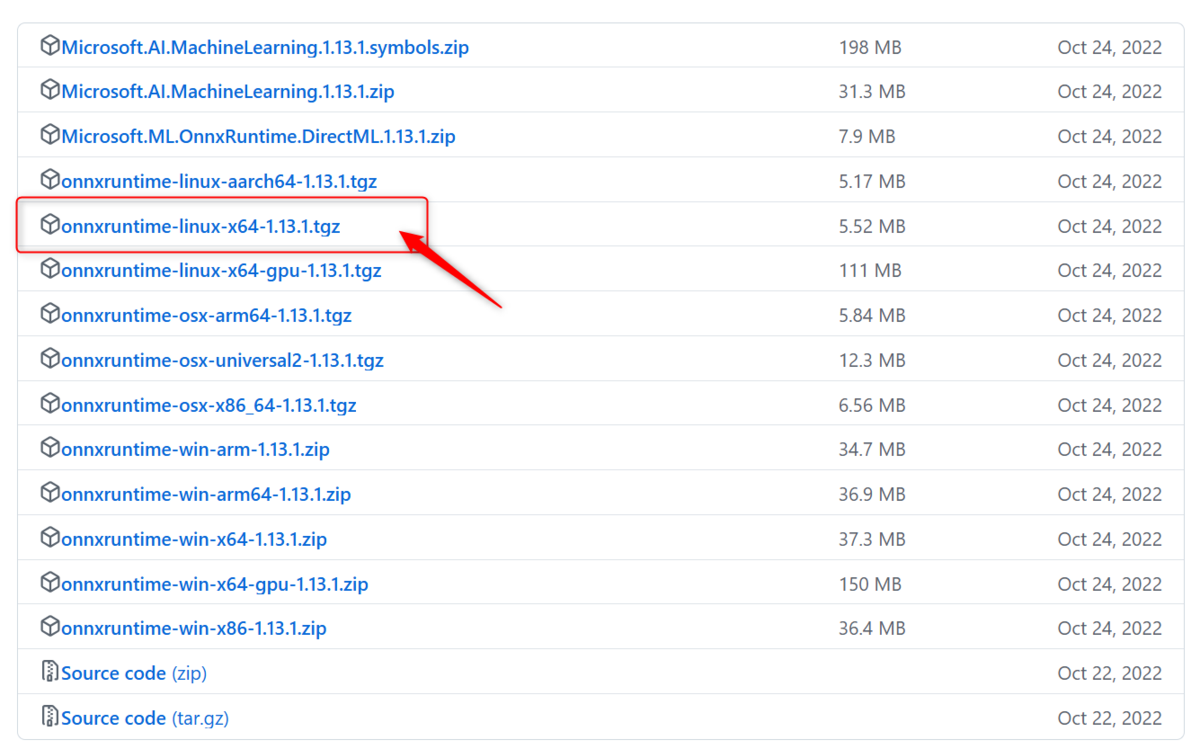
以下のようにインストールを行います。アーキテクチャタイプはLinux x86_64 CPUに対応するlinux-x64を使用します。今回、VOICEVOX COREで使用するのは、最新版ではなくバージョン1.13.1となります。ファイル名はonnxruntime-linux-x64-1.13.1.tgzとなります。
ONNX Runtime(推論用ライブラリ)をダウンロードして展開後にSharedObject(so)ライブラリとしてシンボリックリンクの作成を行います。
$ wget https://github.com/microsoft/onnxruntime/releases/download/v1.13.1/onnxruntime-linux-x64-1.13.1.tgz $ tar zxvf onnxruntime-linux-x64-1.13.1.tgz $ ln -s onnxruntime-linux-x64-1.13.1/lib/libonnxruntime.so.1.13.1
2-3. Open JTalkの辞書のインストール
VOICEVOX COREは辞書を必要とするので日本語テキスト解析用のOpen JTalk辞書ファイルを公式サイトからダウンロードし、任意の場所に配置します。
$ wget https://jaist.dl.sourceforge.net/project/open-jtalk/Dictionary/open_jtalk_dic-1.11/open_jtalk_dic_utf_8-1.11.tar.gz $ tar xzvf open_jtalk_dic_utf_8-1.11.tar.gz
3. Pythonから使用する
インストールが完了したら、以下のコードを使って音声合成を試してみます💪
サンプルコード
以下は、指定したテキストを音声合成し、WAVファイルとして保存する例です。
speak.py
from pathlib import Path from voicevox_core import VoicevoxCore # Open JTalk辞書のパスを指定 open_jtalk_dict_dir = Path("./open_jtalk_dic_utf_8-1.11") # Coreの初期化 core = VoicevoxCore(open_jtalk_dict_dir=open_jtalk_dict_dir) # 使用する話者IDを指定 speaker_id = 1 # 1:ずんだもん,2:四国めたん etc text = "からあげにレモンをかけることは禁止となっています。" # モデルのロード if not core.is_model_loaded(speaker_id): core.load_model(speaker_id) # 音声合成 wave_bytes = core.tts(text, speaker_id) # WAVファイルとして保存 with open("output.wav", "wb") as f: f.write(wave_bytes)
これで、テキストファイルの読み上げ音声の作成ができました。
ソースコード改良版
先ほどはテキストやファイル名がソースコードに埋め込まれていたので、少し改良を行ってコマンドライン引数で指定できるようにしました。以下のように実行します。
$ python voicevox_utils.py --text "こんにちは" --output_file "greeting.wav" --speaker_id 1 $ python voicevox_utils.py --input_file "input.txt" --output_file "output.wav" --speaker_id 2
voicevox_utils.py ソースコード
from pathlib import Path from voicevox_core import VoicevoxCore import argparse import os def synthesize_speech( text: str = None, input_file: str = None, output_file: str = "output.wav", speaker_id: int = 1, dictionary_path: str = "./open_jtalk_dic_utf_8-1.11" ) -> None: """ テキストまたはテキストファイルから音声を合成し、WAVファイルとして保存します。 Args: text (str): 合成するテキスト。 input_file (str): 入力テキストが記載されたファイルのパス。 output_file (str): 出力するWAVファイルのパス。 speaker_id (int): 使用する話者のID。 dictionary_path (str): Open JTalk辞書のパス。 Raises: ValueError: `text` または `input_file` が提供されない場合。 """ if not text and not input_file: raise ValueError("`text` または `input_file` のいずれかを指定してください。") if input_file: if not os.path.exists(input_file): raise FileNotFoundError(f"入力ファイル '{input_file}' が存在しません。") with open(input_file, "r", encoding="utf-8") as f: text = f.read().strip() if not text: raise ValueError("テキストが空です。") # VOICEVOX COREの初期化 core = VoicevoxCore(open_jtalk_dict_dir=Path(dictionary_path)) # モデルがロードされていない場合はロード if not core.is_model_loaded(speaker_id): core.load_model(speaker_id) # テキスト音声合成を実行 wave_bytes = core.tts(text, speaker_id) # 出力をWAVファイルとして保存 with open(output_file, "wb") as f: f.write(wave_bytes) def main(): """ コマンドライン引数を解析し、音声合成を実行します。 """ parser = argparse.ArgumentParser( description="VOICEVOX COREを使用して音声を合成します。", epilog=""" 使用例: python voicevox_utils.py --text "こんにちは" --output_file "greeting.wav" --speaker_id 1 python voicevox_utils.py --input_file "input.txt" --output_file "output.wav" --speaker_id 2 """, formatter_class=argparse.RawTextHelpFormatter ) parser.add_argument("--text", type=str, help="合成するテキスト。") parser.add_argument("--input_file", type=str, help="入力テキストが記載されたファイルのパス。") parser.add_argument("--output_file", type=str, default="output.wav", help="出力するWAVファイルのパス。") parser.add_argument("--speaker_id", type=int, default=1, help="使用する話者のID。") parser.add_argument("--dictionary_path", type=str, default="./open_jtalk_dic_utf_8-1.11", help="Open JTalk辞書のパス。") # 引数が指定されない場合に--helpを表示 if not any(arg.startswith("--") for arg in os.sys.argv[1:]): parser.print_help() exit() args = parser.parse_args() synthesize_speech( text=args.text, input_file=args.input_file, output_file=args.output_file, speaker_id=args.speaker_id, dictionary_path=args.dictionary_path ) if __name__ == "__main__": main()
このソースコードを再利用するには以下のようにします。
読み上げるテキストを直接指定する場合
from voicevox_utils import synthesize_speech synthesize_speech( text="こんにちは、世界!", output_file="hello_world.wav", speaker_id=1, dictionary_path="./open_jtalk_dic_utf_8-1.11" )
読み上げるテキストをファイルで与える場合
from voicevox_utils import synthesize_speech synthesize_speech( input_file="input.txt", output_file="output.wav", speaker_id=2, dictionary_path="./open_jtalk_dic_utf_8-1.11" )
おわりに
今回は、WSL環境でのVOICEVOX COREの導入から、Pythonを使用した基本的な音声合成の実装をまとめてみました。RaspberryPiでは既にやっていましたが、WSLでも同様にできてよかったです。
VOICEVOX COREは無料で使える高品質な音声合成エンジンであり、プログラムから簡単に制御できる点が特徴です。私はこれを音声認識プログラムのマイク入力のソースとして使用していきます。