Pythonを使用してLLMのプロンプトを書く中で、わりとPythonの文字列の扱いの奥深さを感じたので、今回はPythonでよく使う文字列処理の便利な小技をメモしておこうと思います。特にf文字列のネストや、r文字列、3重クォート文字列(""")の組み合わせについての内容になります。
※今回のエントリでは、f文字列のネストとは「f文字列の再帰的な使用」を呼ぶことにします。
Pythonの文字列処理、知っているようで知らない小技
普段何気なく使っているPythonの文字列処理ですが、f文字列(フォーマット文字列)をネストしたり、r文字列(raw文字列)と組み合わせたりすることで、より柔軟な文字列操作が可能になります。
はじめに
この記事で紹介する機能の多くはPythonのバージョンに依存します。 内容を試す際は、お使いのPythonのバージョンを確認してください。
対象としているPythonのバージョン
古いバージョンのPythonを使用している場合は、まずバージョンアップを検討することをお勧めします。
f文字列のネスト機能
f文字列の基本
f文字列は、文字列の中に変数や式を埋め込むことができる便利な機能です。文字列のクォート("や')の前にfをつけ、文字列内の{ }の中に変数や式を書くことで、埋め込みが可能になります。
f文字列の例
name = "Uepon" age = 100 print(f"Name: {name}, Age: {age}") # 出力: Name: Uepon, Age: 100
f文字列のネスト
自分も知らなかったのですが、実は、f文字列の中に更にf文字列を入れることができます。
やり方はf文字列の変数の{ }の中に更にf文字列を入れるというものです。
name = "Tama" age = 25 # f文字列の中にf文字列を入れる print(f"User Info: {f'Name is {name}, Age is {age}'}")
この機能は、複雑な文字列テンプレートを作成する際に便利です。ただし、深いネストは可読性を損なう可能性があるので注意が必要です。 変数を使えば簡単にできますが、変数を使うまででもないときには使えるテクニックかなと思います。また以下のような見やすい表現にするパターンでも使えると思います。
参考
r文字列との組み合わせ
r文字列とは
r文字列は、バックスラッシュ(\)をエスケープ文字として解釈しない文字列です。
主にファイルパスやURLを扱う際に重宝します。
# 通常の文字列 print("C:\\Users\\Documents") # バックスラッシュをエスケープする必要がある # r文字列 print(r"C:\Users\Documents") # そのまま書ける
f文字列とr文字列の組み合わせ
f文字列とr文字列を組み合わせることで、変数を含むパスの文字列を簡単に作成できます。
user = "uepon" # fr文字列として使用 path = fr"C:\Users\{user}\Documents" print(path) # 出力: C:\Users\uepon\Documents # f文字列の中にr文字列を入れることも可能 print(f"Path is: {r'C:\Users'}\{user}")
3重クォート文字列(""")との組み合わせ
3重クォート文字列は、改行を含む長い文字列を見やすく書くための機能です。 これらも他の文字列形式と組み合わせることができます。
name = "uepon" template = f""" Dear {name}, This is a multi-line message for you. Current path: {r'C:\Program Files'} """
使用上の注意点
1. ネストの深さに注意
ネストは便利ですが、あまり深くしてしまうとソースが読みにくくなります。
# 悪い例:ネストが深すぎて読みにくい print(f"Data: {f'User: {f'Name: {name}'}'}") # 良い例:適度な深さで読みやすい user_info = f"Name: {name}" print(f"Data: {user_info}")
2. fr文字列(rf文字列)の順序は関係ない
自分も関係あると思っていたのですが、fr文字列とrf文字列はどちらも同じ処理になります。
- f(フォーマット)が先に処理され、その後*r(raw文字列)が適用される、というような評価順序はない**
- r(raw文字列)は「リテラル文字列の解釈方法」に影響し、f(フォーマット文字列)は「式の展開」に影響する
- fr"..." と rf"..." はまったく同じ動作をする
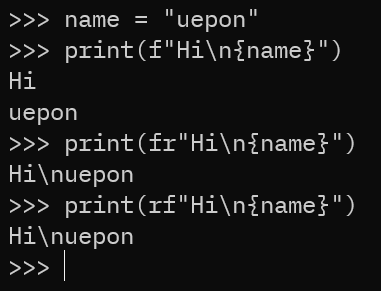
# \nが含まれるケース name = "uepon" print(f"Hi\n{name}") # Hi # test (\nが改行として解釈される) print(fr"Hi\n{name}") # Hi\ntest (\nがそのまま文字として扱われる) print(rf"Hi\n{name}") # Hi\ntest (同じ結果)
使用例
ログファイルのパスを生成する例は以下のようになります。
def create_log_path(username, date): # 複数の文字列機能を組み合わせて使用 base_path = fr"C:\Logs\{username}" log_template = f""" LOG FILE User: {username} Date: {date} Path: {base_path} """ return log_template # 使用例 print(create_log_path("uepon", "2024-02-10"))
まとめ
- f文字列は他のf文字列の中にネストできる
- r文字列とf文字列は組み合わせ可能(fr文字列・df文字列は同じ処理)
- 3重クォート文字列(""")は他の文字列形式と自由に組み合わせられる
- ネストが深くなりすぎないように注意する
- 過信せず、出力を確認しながら使用する
奥深い内容でした😊