折角お借りできたGPUの搭載されたPCなのでゲームをプレイとはならず、仮想環境でGPUを使ったAI(?)な環境整備とベンチマークを行ってみました。前回はWSL2環境でのUbuntuを使って環境整備を行っていましたが、さすがに色々なパッケージや環境変数設定、バージョンのチェックがありインストールしていくのはかなり大変なので、できれば事前に整備されたOSコンテナのイメージをしようできればいいのになと思っていました。そんななか、いろいろ検索していき、WindowsのDocker Desktop環境(WSL2のバックエンド使用)でもGPUを使用することができるようになっていたようです(パフォーマンスも改善されているようです)。そこで、今回はDocker環境下でも同様にGPUの動作ができるかを検証してみました。
今回は以下の情報がなければ実現できませんでした。ありがとうございます。
qiita.com
ただ、そのままでうまく行かない部分もあったのでその部分は変更しています。
今回使用したPC環境
Windows 10 Insider Preview Build 20150 (以降) のインストール
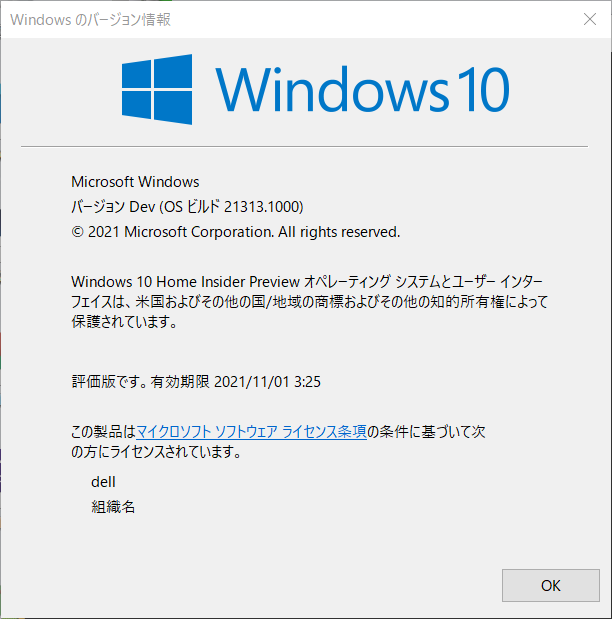
まずは、Windows 10 Insider Previewに参加します。Build 20150 (以降)でないとWSL2のバックエンドからのGPU使用はできないようです。現在のOSバージョンはwinverコマンドで確認してください。
今回使用しているバージョンは以下のようになっていました。
あとは以下のエントリーを参考にして、WSL2を有効化してください。
uepon.hatenadiary.com
NVIDIA Drivers for CUDA on WSL のインストール
WSLで使用可能なNVIDIAのドライバ(Windows側のドライバ)は以下からダウンロードします。前回のエントリーで使用したものと同じものになります。(ダウンロードにはユーザログインが必要)
developer.nvidia.com
ダウンロード後インストールすると以下のようなバージョンになっていました(2021.02.24現在)

Windows StoreアプリからUbuntu18.04をインストールします。

Ubuntuのインストールが終わったら、【起動】ボタンをクリックして起動します。
初回起動時はユーザ名とパスワードの登録を行うことになります。入力を行えば無事にログインができるようになります。
今回インストールしたUbuntuはGPUの認識確認および最終的なDockerイメージを起動するための設定用のOSになります。そのたま少しバージョンが古くても問題はありません。
apt関連の更新を行います。前回のエントリではこの時点でPythonのインストールを行っていましたが、今回は設定用のOSのため、Pythonのインストールをあえて行っていません。
sudo apt update
sudo apt -yV upgrade
あとは、CUDAツールキットをインストールします。今回インストールするのは11.2となります。
$ sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
$ sudo sh -c 'echo "deb http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 /" > /etc/apt/sources.list.d/cuda.list'
$ sudo apt update
$ sudo apt install -y cuda-toolkit-11-2
※ NVIDIA ドライバ 465.42 かつ Windows Insider Preview ビルド 21292 以降で、CUDA 11.2 がサポートされたようです。
/usr/local/cuda/samplesにサンプルがあるので、その中にあるmakefileをビルドして、出来上がった実行ファイルdeviceQueryを実行してGPUの認識情報が表示されていれば正常に認識されています。
$ cd /usr/local/cuda/samples
$ sudo make
$ cd /usr/local/cuda/samples/bin/x86_64/linux/release
$ ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce RTX 2080 Super with Max-Q Design"
CUDA Driver Version / Runtime Version 11.3 / 11.2
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 8192 MBytes (8589934592 bytes)
(48) Multiprocessors, ( 64) CUDA Cores/MP: 3072 CUDA Cores
GPU Max Clock rate: 1230 MHz (1.23 GHz)
Memory Clock rate: 5501 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 65536 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.3, CUDA Runtime Version = 11.2, NumDevs = 1
Result = PASS
実行の様子
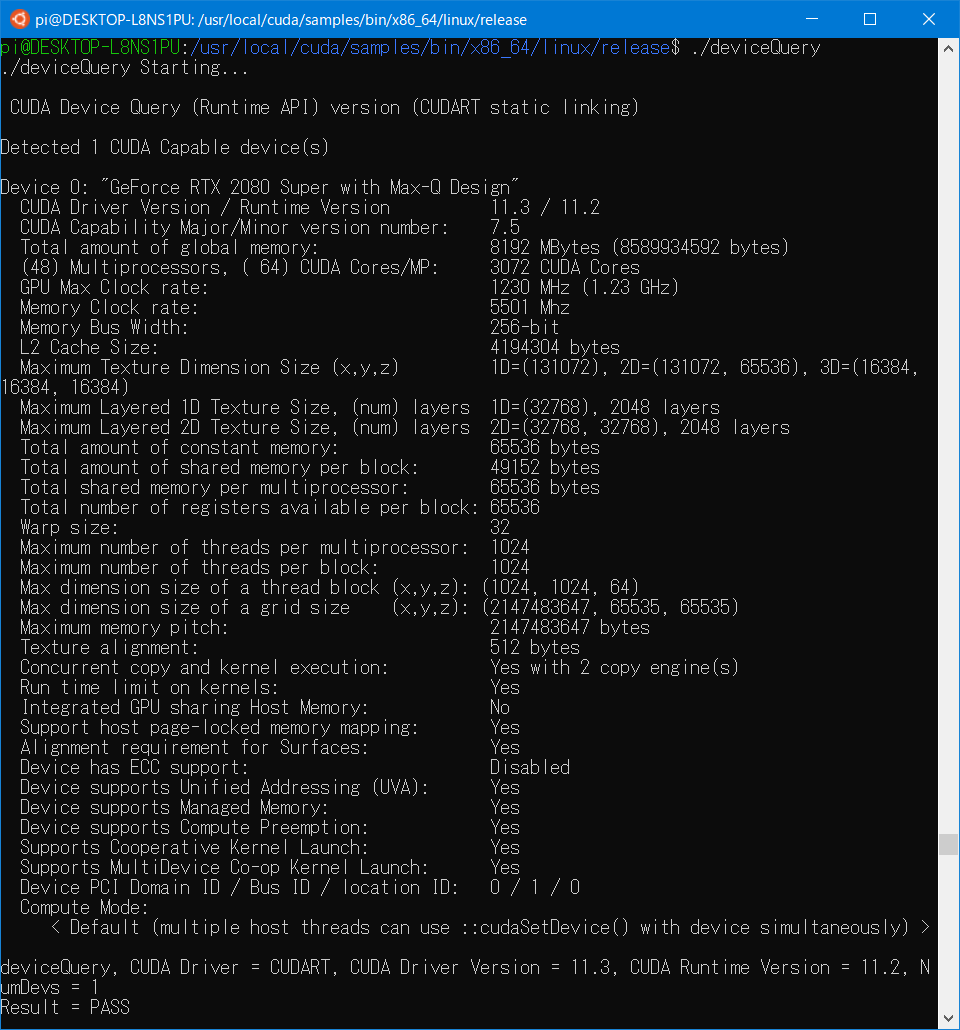
これでWLS2上のUbuntuからGPUの認識が確認できました。
続いてはDocker Desktopをインストールして、Dockerコンテナ側のOSからGPUの機能を使用していきます。
Docker DeesktopのインストールとWSL2との連携
参照したエントリの箇所でいうと、Docker Desktop とその WSL 2 バックエンドを使う方法に該当します。こちらのほうが手順が少ないのでおすすめです。
まずはDocker Desktopをダウンロードしインストールを行っておきます。
参考
uepon.hatenadiary.com
docs.docker.jp
Docker Desktop for Windowsは以下からダウンロードし、インストールを行ってください。
hub.docker.com
インストール後に、WSL2と連携を行います。Docker Desktopを起動して
画面上部にある、【歯車アイコン】のボタンをクリックして、【Settings】の画面に遷移して、【Resources】→【WSL Integration】を選択し、画面内のチェックとトグルを有効化することで
設定前の状態
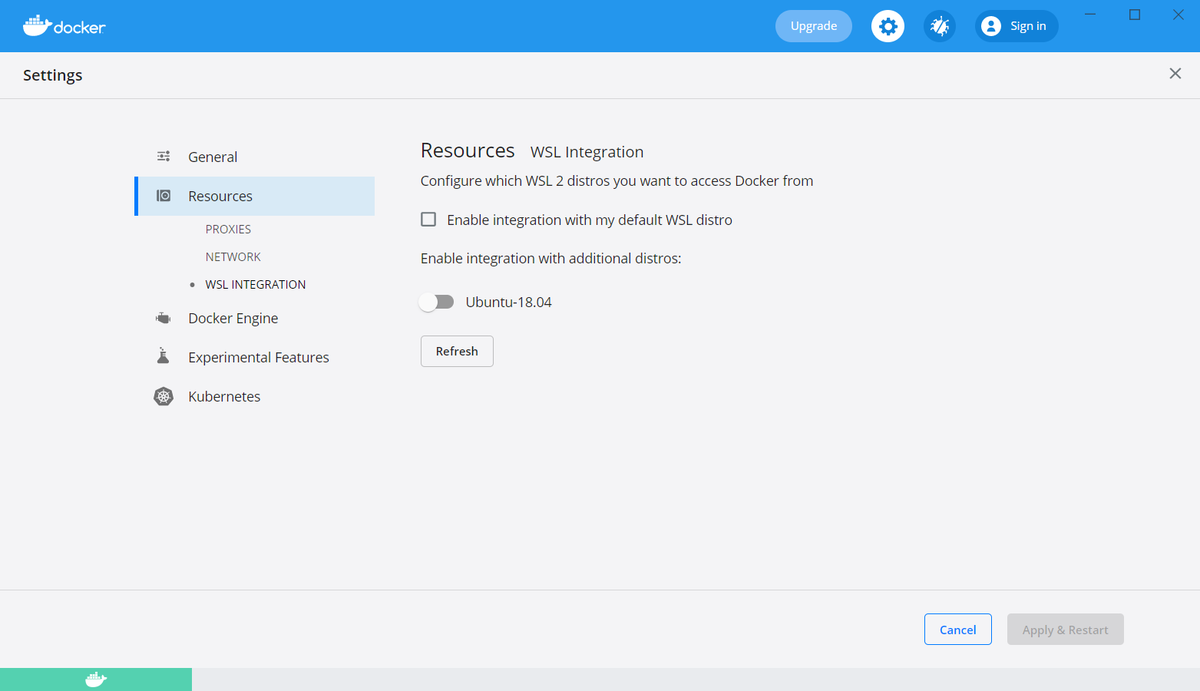
これで、Docker DesktopでのWSL Integrationを有効化する事ができます。
設定後の状態
WSL2上のUbuntuにDockerをインストールするよりも簡単に設定が行えます。
NGC のコンテナイメージを起動する
NGCとはnVIDIA GPU CloudのことでnVIDIAが提供するDockerイメージをいいます。
NGC はディープラーニング、機械学習、HPC のための GPU 対応ソフトウェア総合カタログを提供しています。NGC コンテナーは、高性能かつ導入が容易なソフトウェアを提供します。既に NGC コンテナーを使い、最速の結果を出したという実績もあります。インフラの構築から開放されるので、NGC を利用して、ユーザーは効率の良いモデルの構築、最適なソリューションの実現、短時間でのインサイトの収集に集中できます。
www.nvidia.com
今回はこのコンテナを先程起動したUbuntuでDockerのコンテナを起動していきます。WSL2のUbuntuのsh上で以下を実行します。
今回使用しているコンテナはtensorflow:20.12-tf2-py3のソフトウエア情報はこちらにあります。
docs.nvidia.com
$ sudo docker run --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --gpus all --rm -it nvcr.io/nvidia/tensorflow:20.12-tf2-py3
上記を実行すると、コンテナのダウンロードを開始します。

NGCコンテナは結構大きいので、初回起動時にはダウンロードで時間がかかります。お茶でも飲みに行ったほうがいいと思います。

ダウンロード後にイメージが起動します。プロンプトが$から#になっているので、それで起動の判別ができると思います。起動したsh上で以下のように実行を行います。(参考にしたエントリ通りのテストになります)
--export_dir=/tmp \
--display_every=10 \
--num_iter=100 \
--iter_unit=batch \
--batch_size=128 \
--precision=fp16
ですが実行すると、以下のようなエラーメッセージが表示されます。コンテナの実行なのでエラーが発生します。
実行時のログ
# /workspace/nvidia-examples/cnn/resnet.py \
--export_dir=/tmp \
--display_every=10 \
--num_iter=100 \
--iter_unit=batch \
--batch_size=128 \
--precision=fp16
(中略)
******************************************************************************************
2021-02-24 13:22:05.788980: W tensorflow/core/framework/op_kernel.cc:1767] OP_REQUIRES failed at tile_ops.cc:223 : Resource exhausted: OOM when allocating tensor with shape[128,7,7,2048] and type half on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
Traceback (most recent call last):
File "/workspace/nvidia-examples/cnn/resnet.py", line 50, in <module>
nvutils.train(resnet50, args)
File "/workspace/nvidia-examples/cnn/nvutils/runner.py", line 218, in train
model.fit(train_input, epochs=num_epochs, callbacks=training_hooks,
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/keras/engine/training.py", line 108, in _method_wrapper
return method(self, *args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/keras/engine/training.py", line 1098, in fit
tmp_logs = train_function(iterator)
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/eager/def_function.py", line 780, in __call__
result = self._call(*args, **kwds)
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/eager/def_function.py", line 840, in _call
return self._stateless_fn(*args, **kwds)
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/eager/function.py", line 2829, in __call__
return graph_function._filtered_call(args, kwargs) # pylint: disable=protected-access
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/eager/function.py", line 1843, in _filtered_call
return self._call_flat(
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/eager/function.py", line 1923, in _call_flat
return self._build_call_outputs(self._inference_function.call(
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/eager/function.py", line 545, in call
outputs = execute.execute(
File "/usr/local/lib/python3.8/dist-packages/tensorflow/python/eager/execute.py", line 59, in quick_execute
tensors = pywrap_tfe.TFE_Py_Execute(ctx._handle, device_name, op_name,
tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[2048,1000] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node gradient_tape/resnet50/fc1000/MatMul/Cast/Cast (defined at workspace/nvidia-examples/cnn/nvutils/runner.py:218) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[Op:__inference_train_function_13556]
Function call stack:
train_function
エラーメッセージ中のOOMってなんだろうと思ったらOut of memory (OOM)ということのようです。そのため、今回はオプションで使用していた--batch_sizeの値が128になっていたので
64に変更してみたらうまく実行されました。このコマンドの実行の内容の詳細がわかっていないので、適切な数値がよくわかりませんが、GPU側の搭載メモリによるものと予想されます。GPUによっては調整が必要のようです。
以下のようにすることでうまく実行ができました。
--export_dir=/tmp \
--display_every=10 \
--num_iter=100 \
--iter_unit=batch \
--batch_size=64 \
--precision=fp16
成功時のログ
# /workspace/nvidia-examples/cnn/resnet.py \
--export_dir=/tmp \
--display_every=10 \
--num_iter=100 \
--iter_unit=batch \
--batch_size=64 \
--precision=fp16
(中略)
global_step: 10 images_per_sec: 31.6
global_step: 20 images_per_sec: 393.3
global_step: 30 images_per_sec: 392.9
global_step: 40 images_per_sec: 392.4
global_step: 50 images_per_sec: 391.2
global_step: 60 images_per_sec: 393.3
global_step: 70 images_per_sec: 390.0
global_step: 80 images_per_sec: 394.1
global_step: 90 images_per_sec: 388.2
global_step: 100 images_per_sec: 390.5
epoch: 0 time_taken: 35.0
100/100 - 22s - loss: 11.4782 - top1: 0.2569 - top5: 0.3672
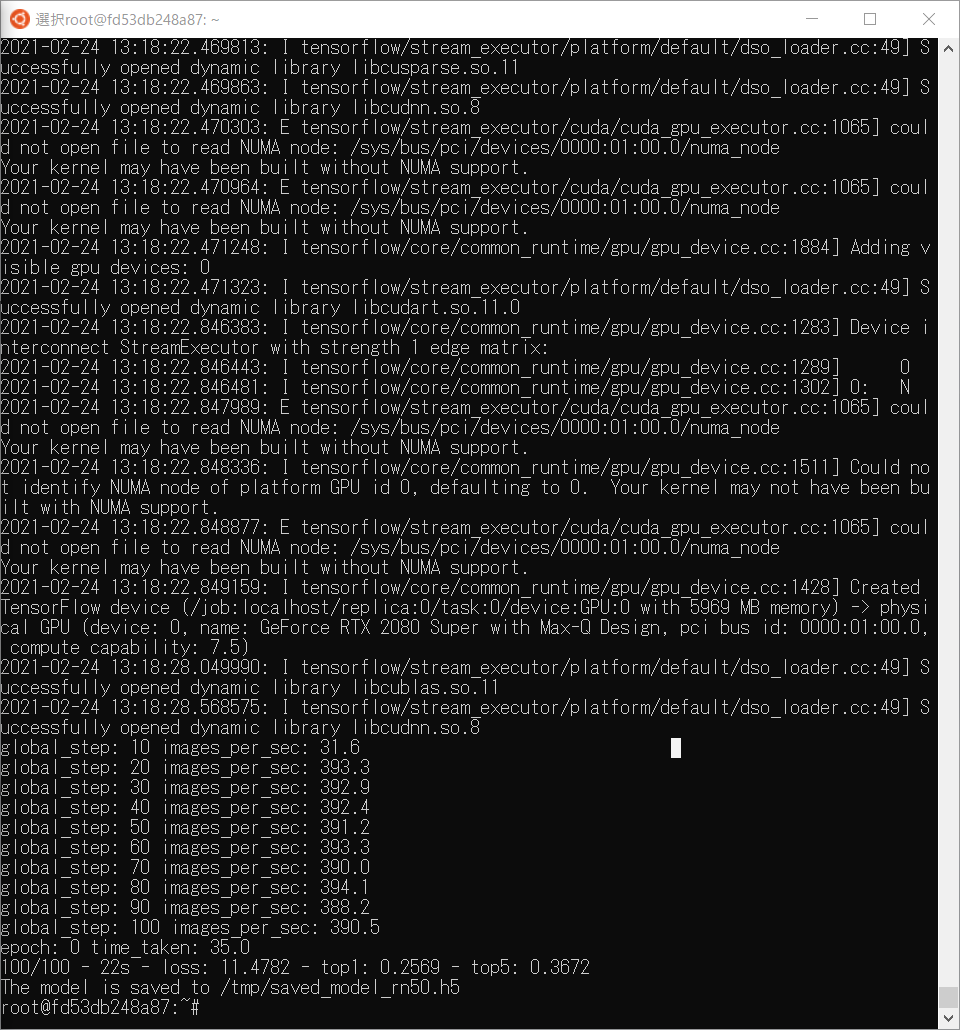
オプションの値を変えることでタスクマネージャーのGPUメモリの消費量が減っていたので効果があったみたいです。でもメモリの値はオーバーフローするほどにそこまで高くなかったのですが…
OOMエラーの対処に関しては以下の情報が助けになりました感謝!
qiita.com
bto.applied.ne.jp
おわりに
前回のエントリではアプリケーションやライブラリのバージョン、OSのバージョンなど気をつけることが大量にありましたが、コンテナではそこまで気にしなくても環境の設定が完了できるのはやはり魅力です。DockerからNGCコンテナを使用する方法をおすすめいたします。
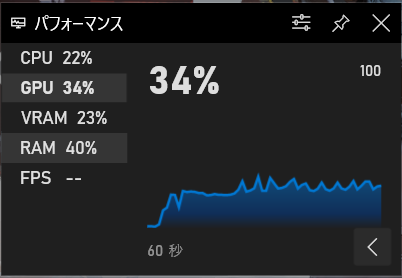
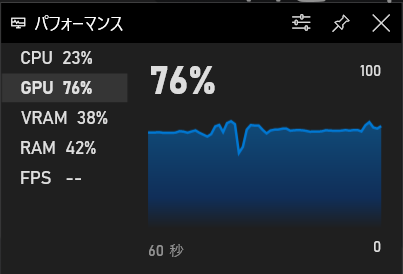
これまでゲーミングPCのモニタなのにゲームもせずにベンチマークやAI系(?)の環境設定ばかりやっていたので、そろそろデルさんに怒られそう。
でも、実際には、AIをやるぜーっていって意気込んでGPU搭載したPCを購入したにもかかわらずいろいろ挫折して、最終的にゲーミングPCになることだってあると思います。そう思えば、自分の書いた情報も役に立つのかも。
次回はちょっとだけゲームを立ち上げてみて、状況を確認してみます。3Dのゲームをほとんどやらないので多分、感想しかでてこないと思いますが。
参考
uepon.hatenadiary.com